第4期:Cursor定价风波
深度剖析Cursor按token计费引发的行业信任危机与Claude Code崛起背后的技术逻辑,揭示AI编程工具真正的护城河所在,并精选25篇前沿技术文章,涵盖AI Agent架构、性能优化实践、Web标准演进等核心议题,为技术决策者提供全景式的行业洞察与实践指导。
对于所有的文章,我都会进行深度总结,可以先打开总结,如果看了总结之后,觉得有价值,再去看原文,因为原文可能会有很多细节,而总结会帮你过滤掉很多细节,只保留最重要的信息。

卷首语
随着 Cursor 的定价策略调整,Cursor 的计费方式也存在着一个严重的黑盒问题,之前改成了无限量使用,按时间段内的使用量限速,现在改成了按照 token 计费,官方的说法也很模糊,他们给出了下面的解释:
也就是说新的计费方式缩量了,Claude Pro 订阅大概只能使用 Claude Sonnet 模型 225 次左右,即使换回老得500次快速请求计费模式,也会出现一次请求消耗多条请求。
这件事直接导致 Cursor 用户对于官方的信任危机,很多用户开始质疑 Cursor 的定价策略,甚至有人开始考虑使用其他 AI 编程工具。
比如我自己,就暂时取消了 Cursor 的自动订阅,先观望后续事情发展,我个人感觉这事情闹得这么大,Cursor 的定价还要调整。
随着 Claude Code 和 Gemini CLI 的发布,尤其是 Claude Code,口碑极佳,几乎没有差评,但是它存在的问题就是注册困难和价格昂贵,封号是所有 AI 工具中最严重的。
所以这就催生了大量的第三方镜像商,也带动了大量相关产业的发展,因为它的使用不方便,所以很多人开始写软文,写教程,写视频,写博客,写文章,写评论,来推广 Claude Code,然后销售镜像和账号。
就我个人而言,我不喜欢这种中间还隔着一层代理商的使用方式,这也是我迟迟没有体验 Claude Code 的原因。
就我个人搜集到的资料,通过 CLI 拥有下面的一些好处:
不依赖于其它编辑器,直接在终端中打开,占用资源少,速度快,而且可以和其它工具进行集成,Cursor 这种编辑器由于是基于 VSCode 的,所以对前端开发是非常友好的,但是对于JAVA开发来说,那么他们不仅需要打开 Cursor,还需要打开 IDEA。
由于编程用的模型几乎都是 Claude 的模型,通过 Cursor 使用,那么 Cursor 相当于在中间做了一个中间商,先将代码发送到 Cursor,然后由 Cursor 将代码发送到 Claude,然后由 Claude 返回结果,再由 Cursor 将结果显示出来。
而通过 CLI 的形式,那么就不需要经过 Cursor 这个中间商,直接将代码发送到 Claude,然后由 Claude 返回结果,然后直接在终端中显示出来。
好处可以说是显而易见的,少了中间商赚差价,中间商如果在抢占用户阶段,就会给出大量的优惠策略,但是一旦用户量上来了,那么中间商就会开始考虑如何盈利,就会开始更改定价方式,现在的 Cursor 明显就处于这个阶段。
同样,CLI 也带来了一些困难:
上手难度更高,需要学习一些命令行知识,代码改动不直观,没有办法在改动过程中进行修改,但是据说用过 Claude Code 的人反映,Claude Code 生成的代码质量非常高,几乎不用做什么修改。
而且现在有部分用户已经开始开发对应的图形客户端,比如 Claudia。
那么这些 AI 工具的护城河是什么呢?
我觉得是模型,模型的好坏直接决定了 AI 工具的性能和效果,所以目前手握最强编程模型的 Claude 就有更大的话语权,它可以轻易断供 Windsurf,那么它就可以轻易断供 Cursor。最后可能把自己玩脱,也可能受伤的是用户。
本周头条
1、Cursor 官方在论坛中发布了之前对于订阅策略的描述不正确导致用户误解,现在进行了更正,按照 token 量进行计费,很多用户在大量使用中,就出现了下面的提示。

2、Apache ECharts 6.0 震撼发布・前图无量。

3、自从 Adobe 停止收购 Figma 后,现在Figma 准备上市。

4、苹果公司的论文探讨了大型推理模型的局限性,同时也揭示了 CarPlay Ultra 遇到的困难。

5、随着大模型越来越智能,更多人开始用它来满足自己的情感需求。

6、百度搜索十年来最大的改版,支持超千字长文本输入和 MCP 调用。
7、自 Prompt 工程被提出后,大量的人研究怎么写好 Prompt,现在逐步转向到一个新概念:Context 工程,这是最近各大厂商都在研究的一个热门概念。
8、国际刑事法院(ICC)近日遭遇两年来第二次“高度复杂”的网络攻击,尽管攻击已被侦测并遏制,具体影响和攻击细节未被披露。
深度阅读
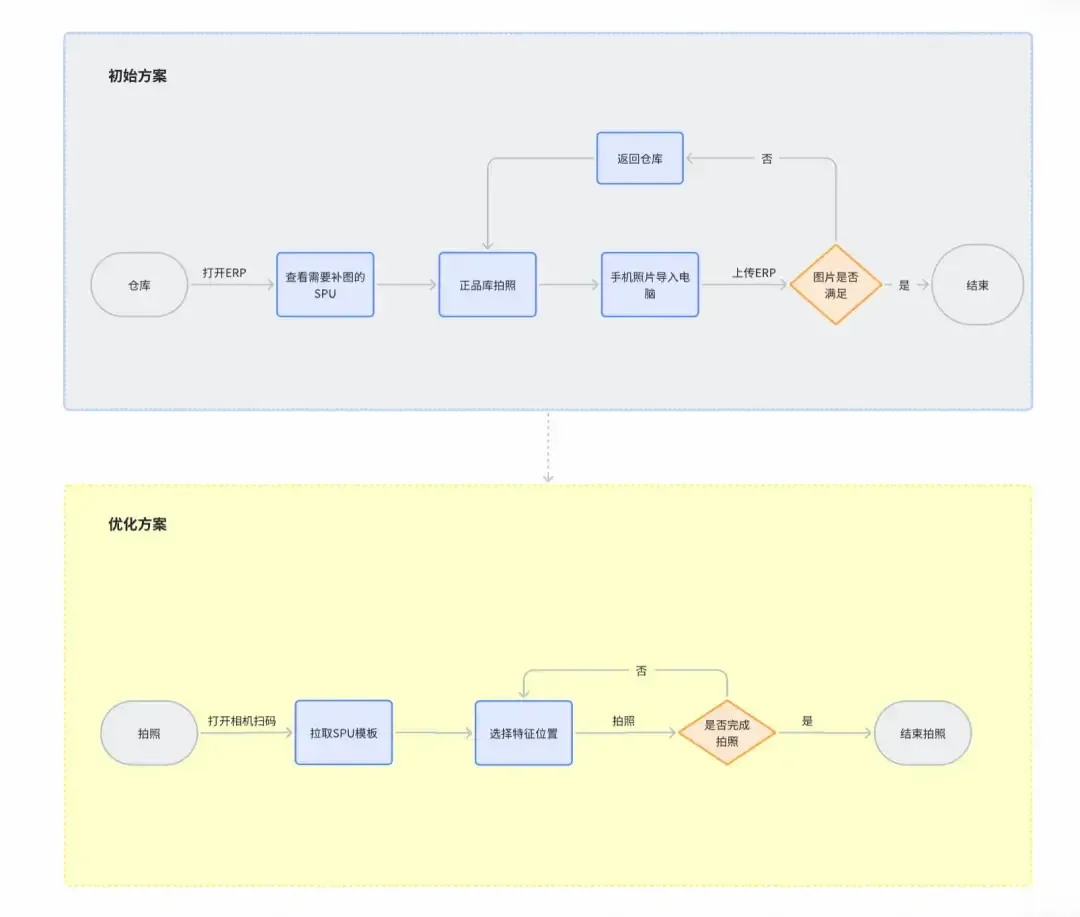
得物通过PWA拍照应用的架构与性能深度优化,突破了高分辨率图片处理的内存与性能瓶颈,实现了移动端高效、稳定的正品图采集,极大提升了作业效率与用户体验,为后续智能化与业务扩展奠定了坚实基础。
深度总结
背景与挑战
得物ERP的正品库拍照流程原本依赖线下操作,效率低下且人力成本高。现有流程中,图片上传繁琐、图片质量受损、操作端单一,导致正品流转效率受限。库内存量巨大,补图流程每日处理量远低于实际需求,难以支撑正品库的快速建设。
技术实现
应用基于WebRTC、HTML5 Canvas和Web Worker。WebRTC负责获取摄像头视频流,Canvas用于捕获视频帧生成图片,Web Worker则承担图像处理任务,避免主线程阻塞。整体架构强调资源精细化管理和容错机制,确保性能优先和稳定性。
性能瓶颈分析
高分辨率图片(如iPhoneX的4032x3024)带来显著的内存压力。单帧内存消耗可达46.5MB,实际单张图片处理峰值更高。移动端设备内存有限,iOS WebKit对单标签页内存有严格上限。视频流与图像处理争夺GPU资源,设备性能差异和浏览器内存管理不可控,进一步加剧问题。连续拍摄时,内存和CPU压力迅速上升,导致页面卡顿、拍照失败甚至进程被终止。
优化策略
- Canvas主线程绘制改为离屏渲染
- 视频流管理与设备参数预热
- 分辨率动态管理
- Web Worker线程独立绘制
- 设备检测与适配策略优化
- 异步上传管理
- 页面reload与历史数据缓存
- 内存分配模型调整
图片处理由原先的toDataURL转为toBlob,减少内存占用和上传体积。引入Web Worker和OffscreenCanvas后,图像处理在独立线程完成,主线程保持响应。ImageBitmap用于高效跨线程传输,避免不必要的内存拷贝。
分块处理策略
为控制内存峰值,采用chunked和chunkedConvert两种分块处理策略。chunked策略将大图像分割为小块,逐块处理,降低单次内存消耗。chunkedConvert则将每块独立压缩为Blob,最后合并,进一步降低峰值但牺牲处理速度。策略根据设备性能动态选择,优先保障低端机型的可用性。
优化效果
- 单张图片处理峰值内存下降33%
- 持久内存占用下降61%
- PWA整体内存优化16-26%
- 用户体验显著提升,拍摄流畅度提高,UI阻塞减少
- 支持一次性拍摄50张高清图片,远超优化前的3张限制
业务成效
日均拍摄件数提升330%,人力成本下降41.18%。PWA项目推动图库建设,拍照数据占比和流转效率均大幅提升,超出业务预期。
未来规划
后续将细化设备能力评估,针对不同设备和业务场景定制优化策略。计划引入更智能的拍摄能力和实时拍摄指导,进一步压缩拍摄时间。拍照H5方案将纳入商品入库流程,提升图库验收入库效率,缩短数据积压周期。
2、如何让 AI 成为你的编程搭档?一次真实重构告诉你答案(中文)

本文以高德商家平台重构实践为例,系统展示了 AI 编程助手 Cursor 如何通过规则驱动、分步拆解和人机协作,实现复杂需求的高效开发,显著提升开发效率,但也需规范流程和人工把控以弥补其局限。
深度总结
背景与工具介绍
开发者一直在追求更高的效率。随着大语言模型的普及,AI编程逐渐成为主流。Cursor是一款基于VS Code的智能代码编辑器,深度集成AI模型。它不仅能用自然语言生成、解释、重构代码,还能理解项目上下文,成为开发者在IDE中的高效助手。
Cursor有三种内置模式:Agent、Ask和Manual。Agent模式可自主学习代码库并进行大范围修改;Ask模式专注于代码理解和答疑,不会修改代码;Manual模式则完全依赖用户指令,不主动探索代码库。Cursor还支持自定义模式,适应不同工作流。
与传统的Copilot等工具相比,Cursor具备更原生的产品形态、更强的开发能力和更深的参与周期。它不仅能在代码开发阶段提供帮助,还能覆盖方案设计、测试等环节。
能力与局限
Cursor的能力受限于底层大模型。模型的“记忆能力”有限,超出范围会导致不稳定。对于跨应用、跨团队的复杂需求,Cursor支持不足。各研发环节的支持能力也不均衡,需要工程上的限制和规范来保证预期效果。
实践流程
本次实践以高德商家平台的“找路指引”模块为例,结合业务需求和技术重构目标,首次全流程使用Cursor。目标包括简化数据模型、优化接口设计、清晰调用链路。
1. 历史逻辑梳理
重构前需梳理历史业务逻辑,剔除废弃部分,重新组织业务编排。对于跨应用接口,需分别梳理各自逻辑,再由Cursor拼接。
2. 规则驱动的接口分析
通过自定义Rules,规范接口分析流程。包括入口定位、调用链追踪、分支逻辑、数据校验、并发控制、异步处理等。输出包括文本流程描述、mermaid流程图、数据模型和关键代码分析。
3. 技术方案设计
在开发前,需明确应用开发规约,形成详细的Rules。包括模块职责、目录结构、命名规范、代码风格、DO对象规范、单元测试结构等。通过概要设计,明确新增和修改部分,再由Cursor生成详细设计,精确到方法、参数、伪代码层面。
4. 代码编写与任务拆解
详细设计后,代码实现基本定型。实际编写时需将任务拆解为小颗粒度,按业务逻辑和技术分层逐步实现。提示词结构化有助于Cursor理解任务目标,提高生成质量。
实践中的问题与应对
在实践过程中,遇到上下文过大导致代码错乱、生成内容跳跃等问题。通过任务拆解、分层实现、结构化提示词等方式,有效提升了代码生成的准确性和可维护性。
效率提升评估
本次实践中,Cursor生成了80%以上的新增代码和文档。开发周期由原计划的16人天缩短至8人天,提效约50%。设计阶段提效有限,但编码阶段提升显著。初次搭建Cursor环境和规则需额外投入,但后续可复用。
结论
Cursor作为AI原生编程工具,在复杂需求的重构和开发中展现出较高的效率提升空间。其能力和局限并存,最大化其价值需依赖合理的工程规范和任务拆解。对于有一定基础的开发者,掌握与AI协作的技巧,将成为提升生产力的重要手段。
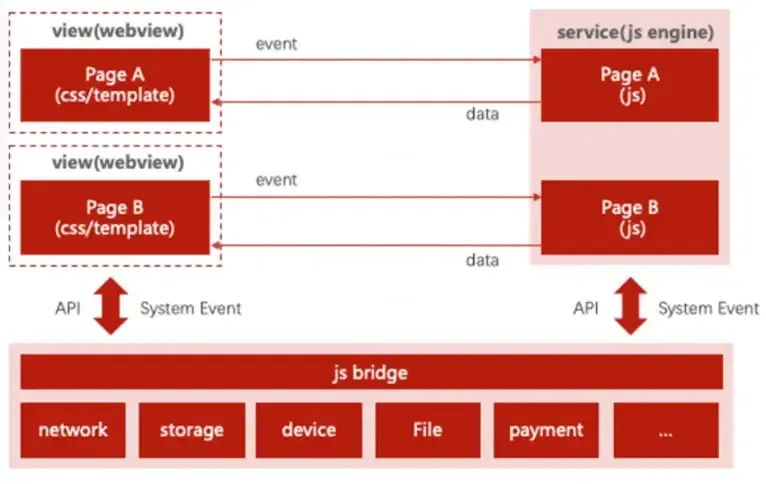
京东小程序通过仓颉语言重构高频JS API,显著优化了API调用效率和主线程负载,getSystemInfo执行时间缩短50%,冷启动提速20%。此次创新为后续多API仓颉化和跨平台高性能开发奠定了基础。
深度总结
背景与架构
京东小程序容器是京东及其关联App的核心组成部分,承载了多种业务场景,包括秒送外卖、买菜、超市店铺等。小程序架构采用双线程设计:JS逻辑线程负责业务逻辑,WebView线程负责页面渲染和交互。两者通过JS Bridge进行通信,API调用主要由Native层实现,部分通过ArkTS派发。
性能瓶颈
在小程序页面加载和活跃阶段,频繁的JS API调用(如Storage、Systeminfo、Network)会导致主线程排队,影响WebView任务处理。线程间数据不共享,跨线程通信需序列化和反序列化,增加响应延迟。JS Bridge与原生交互需调用大量nAPI接口,线程创建和管理成本高,维护难度大。
API调用流程拆解
以getSystemInfo为例,API调用由JS线程发起,主线程通过taskpool处理并返回结果。即使结果已缓存,获取缓存值仍需占用主线程时间,频繁调用时主线程压力显著。
仓颉改造实践
仓颉作为鸿蒙系统官方语言,具备以下优势:
- 线程池能力,JS API执行不占用主线程。
- 线程间天然内存共享,省去序列化和反序列化。
- 与C语言高效互操作,无需nAPI协议接口。
- 可与ArkTS高效互操作,保证API执行逻辑正确。
改造后,JSBridge中加入仓颉API派发逻辑,JS API中实现仓颉版本的getSystemInfo。API调用流程更高效,主线程负担减轻。
优化效果
仓颉改造后,getSystemInfo执行时间缩短50%以上,且不占用主线程。实际冷启动测试中,端到端性能提升约20%,即启动时间减少约500ms。
未来规划
团队计划扩展更多高频API的仓颉化,验证在更多热门场景下的性能收益。还将探索仓颉在网络模块、小程序其他阶段的应用,并利用其高并发和跨平台能力,支持HarmonyOS、Android、iOS和PC平台,降低多端开发复杂度。
招聘信息
京东端技术团队正在招聘APP开发工程师、iOS开发工程师、JAVA后端工程师、浏览器内核专家等岗位,工作地点为北京、上海。
4、Modern Node.js Patterns for 2025(英文)

Node.js 正经历由传统回调和 CommonJS 向 ESM、Web 标准、内建测试及现代异步模式的全面转型,极大提升了开发效率、可维护性和安全性。新特性支持渐进集成,为开发者提供了与 Web 生态高度一致的现代开发体验。
深度总结
Node.js 2025:现代开发模式概览
Node.js 正在经历深刻的变革,逐步向 Web 标准靠拢,减少外部依赖,提升开发体验。以下是当前主流的 Node.js 现代开发模式要点。
模块系统:ESM 成为主流
Node.js 逐步淘汰 CommonJS,全面采用 ES Modules(ESM)。开发者通过 import 和 export 管理模块,内置模块需加 node: 前缀。例如,import { readFile } from 'node:fs/promises' 明确区分内置依赖与第三方包。Top-level await 允许在模块顶层直接使用 await,简化异步初始化流程,无需再用 IIFE 包裹。
内置 Web API:减少外部依赖
Fetch API 已内置,无需再引入 axios、node-fetch 等库。AbortController 提供标准化的操作取消机制,适用于 HTTP 请求、文件操作等多种场景。开发者可通过 AbortSignal 实现超时控制和用户主动取消。
内置测试工具
Node.js 内置 test runner,支持测试用例编写、自动化运行、watch 模式和覆盖率统计。无需再依赖 Jest、Mocha 等第三方测试框架。测试脚本结构清晰,集成度高,提升开发效率。
异步模式与错误处理
async/await 已成为主流,配合 Promise.all 实现并发操作。错误处理采用 try/catch,结合结构化日志记录,便于定位问题。事件流处理推荐使用 AsyncIterator,既能顺序消费事件,又能灵活中断。
流与 Web 标准兼容
Node.js 流 API 进一步标准化,支持与 Web Streams 互转。开发者可用 pipeline 进行流式处理,自动管理资源与错误。Web Streams 兼容性提升,便于在多端环境复用代码。
Worker Threads:多核并行
Worker Threads 适合 CPU 密集型任务。主线程通过 Worker 实现任务分发,保持响应性。数据通过消息传递,主应用不会被阻塞,适合大规模计算场景。
开发体验优化
Node.js 内置 watch mode 和 env-file 支持,开发时无需 nodemon、dotenv 等工具。环境变量自动加载,开发流程更简洁。package.json 脚本配置灵活,便于一键启动、测试。
安全与性能监控
实验性权限模型允许精细控制文件系统和网络访问,提升安全性。perf_hooks 提供内置性能监控,开发者可实时捕捉慢操作,优化性能瓶颈。
应用分发与部署
Node.js 支持将应用打包为单一可执行文件,简化部署流程。适用于 CLI 工具、桌面应用等无需用户单独安装 Node.js 的场景。
错误处理与诊断
推荐自定义 Error 类,结构化记录错误信息与上下文。diagnostics_channel 支持自定义诊断通道,便于监控数据库、HTTP 等关键操作,提升可观测性。
包管理与模块解析
支持 import maps 和内部包解析,简化大型项目的模块管理。动态 import 允许按需加载模块,实现代码分割和功能切换,提升应用灵活性。
结语
Node.js 正在向更高的标准化、易用性和安全性迈进。开发者可逐步引入这些现代模式,提升代码可维护性和开发效率。
5、What’s new in ECMAScript 2025(英文)
ES2025 带来正则重复命名捕获组、Set 集合操作方法、正则子模式修饰符、import 属性与 JSON 模块、迭代器辅助方法、Promise.try()、Float16Array、RegExp.escape() 等重大更新,极大提升了 JavaScript 的表达力、安全性与开发效率。新特性覆盖集合运算、正则灵活性、模块导入、流式数据处理、同步异步统一封装及内存优化,推动语言原生能力持续进化。
深度总结
Duplicate Named Capturing Groups
正则表达式现在允许在不同分支(由 | 分隔)中重复命名捕获组。以往这样会导致语法错误,现在可以正常工作。例如,/(?<version>[0-9]{4})|ES(?<version>[0-9]{2})/ 能同时捕获不同格式的版本号。
Set 方法增强
Set 原型新增了 intersection、union、difference、symmetricDifference、isSubsetOf、isSupersetOf 和 isDisjointFrom。这些方法让集合操作更贴近数学集合论。例如,setOne.intersection(setTwo) 返回两个集合的交集,setOne.union(setTwo) 返回并集。
正则表达式子模式修饰符
现在可以为正则表达式的子模式单独指定修饰符(如 i 表示忽略大小写)。例如,/^(?i:bearer) abc$/ 只对 “bearer” 部分应用忽略大小写,而 “abc” 必须严格小写。这一特性提升了正则表达式的灵活性。
Import Attributes 与 JSON Modules
引入了 import 的 type 属性,明确指定导入资源的 MIME 类型。目前仅支持 JSON 文件。例如,import data from "./data.json" with { type: "json" }。这有助于安全性和资源解析的准确性。
Iterator Helpers
迭代器新增了 map、filter、take、drop、flatMap、reduce、toArray、forEach、some、every、find 等方法,以及静态方法 Iterator.from()。这些方法让迭代器的链式操作变得直观,无需先转为数组。例如,iter.filter(fn) 可直接过滤迭代器内容,iter.drop(10).take(4) 可跳过前10项后取4项。
Promise.try
Promise.try 用于将同步或异步操作包装为 Promise。这样可以统一处理同步和异步异常,无需额外依赖第三方库。例如,Promise.try(() => someSyncFunction()) 能捕获同步抛出的异常并返回 rejected Promise。
Float16Array
新增了 Float16Array,补全了 Float32Array 和 Float64Array 之外的半精度浮点数组。该类型主要用于对内存敏感的图形计算场景。
RegExp.escape
RegExp.escape() 用于将字符串安全地转为正则表达式字面量,避免特殊字符被误解释。例如,RegExp.escape("dog.") 会自动转义点号,确保只匹配 “dog.” 而不是任意字符。
JavaScript 商标问题
“JavaScript” 是 Oracle 的注册商标,因此官方文档和会议多用 ECMAScript 这一名称。社区正在推动商标开放,以便更自由地使用 JavaScript 这一名称。
6、Agent Runtime: A Guide for Technical Teams(英文)
Agent runtime 是 AI 代理的执行环境,使其具备持久性、自主性和复杂任务协作能力。它为开发者、AI 实践者和架构师分别提供了简化开发、生产级智能和基础设施抽象等价值,促进跨职能协作和系统可扩展性。当前市场上,OneReach.ai 的 GSX 是唯一能全面满足 agent runtime 要求的平台。agent runtime 推动 AI 技术从实验走向成熟,成为智能系统建设的关键基础。
深度总结
Agent Runtime:技术团队的全新基础设施
Agent Runtime 是一种为 AI agent 提供持久、自治运行环境的基础设施。它让 AI agent 不再只是简单的请求-响应工具,而是具备持续上下文、目标导向和工具调用能力的智能系统。Agent Runtime 支持 agent 长时间运行、维护状态、访问外部工具,并能与其他系统协作。
对开发者的意义
Agent Runtime 类似于 Node.js 之于 JavaScript。它为多 agent 系统提供统一的运行环境,自动管理状态、工具接入和通信。开发者无需再手动处理繁琐的状态管理和 API 协调,只需专注于 agent 的行为和业务逻辑。开发模式更偏向声明式,描述“做什么”而非“怎么做”,大幅提升开发效率和原型迭代速度。
对 ML/Agentic AI 实践者的价值
Agent Runtime 解决了从研究到生产落地的鸿沟。它为 LLM-based agent 提供生产级的运行环境,自动处理工具调用、上下文切换、记忆管理和系统集成。agent 能拥有持久记忆、长期目标,并能从交互中持续学习。上下文管理和工具集成标准化,agent 可以像真实的自治工作者一样调用 API、访问数据库。平台还提供监控和调试能力,便于持续优化 agent 行为。
对架构师与平台工程师的作用
Agent Runtime 是新一层的基础设施抽象。它简化了 AI 系统的部署和管理,支持分布式 agent 协作、负载均衡、容错和可扩展性。架构师可以像设计 serverless 系统一样,部署 agent 而非微服务。业务逻辑与基础设施解耦,系统更易维护和扩展。平台工程师可在 runtime 层实现统一的部署、监控和安全策略,提升系统的可管理性和合规性。
跨职能的协作基础
Agent Runtime 为不同技术角色提供统一的开发、部署和运维环境。开发者、ML 实践者和架构师可以在同一平台协作,减少沟通成本,加快开发和上线速度。平台提供一致的 API、标准化的部署模式和共享工具链,支持多样化的技术需求。
选型与未来趋势
目前市场上具备完整 Agent Runtime 能力的平台极为稀缺。OneReach.ai 的 Generative Studio X(GSX)是少数能覆盖多 agent 协作、持久记忆、工具集成和生产级可靠性的产品。企业在选型时需关注平台是否支持多 agent 协作、持久状态管理、分布式工作流和高可用性。Agent Runtime 的普及将推动 AI 应用从实验走向生产,技术团队也将从基础设施建设转向智能应用开发。
7、Paradigms for Computation(英文)
文章回顾了计算理论从递归理论到机器学习再到大模型的演变,指出传统范式低估了输入和学习的重要性,现代AI已超出现有理论框架,未来对其本质的理解仍充满挑战。
深度总结
计算范式的演变
本文探讨了计算机科学中“计算”这一核心概念的历史变迁。作者指出,早期计算理论以递归理论为基础,强调固定程序和严格的算法定义。这种范式下,计算被视为一组有限、明确的指令,输入结构简单,目标是获得确定性结果。例如,图灵机模型假设程序和输入是分离的,程序本身不会随着输入的变化而变化。
递归理论的局限
20世纪的递归理论强调数学逻辑的极限,如哥德尔不完备定理。部分学者(如Penrose)据此认为,计算机无法实现人类的创造力,因为数学理解无法被“盲目计算”所取代。然而,随着计算机能力的提升,这种观点逐渐被现实挑战。作者认为,递归理论未能充分考虑到输入的复杂性和动态性。现实中的计算系统,尤其是现代AI,能够持续接收丰富的输入并自我调整,这与早期理论假设的“黑箱”程序有本质区别。
学习与不确定性
作者提出,传统理论忽视了“学习”这一过程。递归理论关注的是算法的正确性,而现代学习算法则允许一定的失败概率。例如,随机算法通过引入随机性,形成了一个算法族,能够适应更复杂的输入环境。这种算法在面对大规模、结构复杂的数据时表现出更强的适应性。作者进一步指出,20世纪的理论很少关注算法在实际运行中可能出现的失败或不确定性。
计算学习理论与神经网络
进入21世纪,计算学习理论(CLT)成为主流,强调统计学习和概率保证。CLT关注的是人类可解释的算法,并对其性能给出概率性分析。然而,随着神经网络和大规模预训练模型(如LLM)的兴起,CLT的解释力逐渐减弱。神经网络的泛化能力和高效的“in-context learning”难以用传统理论解释。预训练过程本质上是一种元学习,使模型在部署前就具备了强大的适应能力。
理论与实践的脱节
作者认为,当前的AI系统更像是庞大的电路而非传统意义上的算法。电路模型强调非均匀性和规模化,理论上可以在固定输入规模下解决任何问题,但缺乏可解释性。计算复杂性理论在电路模型下难以给出有意义的下界,这使得我们难以理解深度学习模型的内部机制。作者对未来能否建立严谨的深度学习理论持谨慎态度,认为对神经网络的理解可能永远停留在间接层面。
结论性思考
本文强调,计算范式的演变反映了理论与实践的不断碰撞。早期的递归理论和逻辑范式已无法解释现代AI的复杂性。学习、随机性和大规模电路成为新的研究重点,但理论体系尚未跟上技术发展的步伐。对于从业者而言,理解这些范式的变迁有助于更好地把握AI系统的本质和未来发展方向。
8、AV1 @ Scale: Film Grain Synthesis, The Awakening(英文)

Netflix大规模部署AV1 Film Grain Synthesis技术,通过建模和动态调整胶片颗粒,实现高保真还原与平均36%码率节省,显著提升视觉质量和播放流畅度,推动高分辨率流媒体体验普及。
深度总结
AV1 Film Grain Synthesis(FGS)在Netflix的应用
AV1 Film Grain Synthesis(FGS)是一项针对视频流媒体的创新技术,旨在在压缩视频时保留电影胶片颗粒的艺术效果,同时显著降低码率。传统压缩算法在处理随机性极强的胶片颗粒时,常常面临保真与文件体积之间的权衡。FGS通过建模和重建颗粒,实现了高效的数据利用和视觉质量提升。
胶片颗粒的建模与合成
FGS主要包含两个核心部分:
-
Film Grain Pattern:利用自回归(AR)模型还原颗粒的空间相关性。具体做法是先对原始视频去噪,计算残差以捕捉噪声特征。通过调整AR系数,可以控制颗粒的粗细。最终生成64x64的噪声模板,播放时从中提取32x32的随机块叠加到解码后的视频帧上。
-
Film Grain Intensity:通过缩放函数(scaling function)动态调整颗粒在不同亮度下的强度。该函数在编码阶段估算,采用分段线性方式描述像素值与噪声强度的关系。这样可以根据画面亮度和色彩,精准还原原始视频的颗粒感。
编码流程中,首先去除原视频的颗粒,压缩后将颗粒的模式和强度参数与视频数据一同传输。解码时再基于这些参数重建颗粒并叠加回视频,实现高效还原。
视觉质量与码率优化
启用FGS后,Netflix在高分辨率(1080p及以上)视频中实现了平均36%的码率下降。以《They Cloned Tyrone》为例,常规AV1编码需8274 kbps,而FGS仅需2804 kbps,颗粒保真度更高,且压缩伪影更少。对于低分辨率视频,码率下降幅度较小,主要因为下采样过程已过滤部分噪声。
FGS合成的噪声还能掩盖压缩伪影,提升主观观感。常规像素级质量评价(如PSNR、VMAF)难以准确反映FGS的优势,但内部评估显示视觉体验有明显提升。
用户体验与系统表现
Netflix通过A/B测试验证了FGS的实际效果,主要改进包括:
- 初始和平均码率分别降低24%和31.6%,带宽和存储需求同步下降
- 播放错误率下降约3%
- 缓冲次数减少10%,缓冲时长缩短5%
- 启动播放延迟缩短10%
- 播放稳定性提升,码率波动和用户拖动播放条的时间均减少10%
- 4K设备下,0.7%的观看时长从低分辨率转向2160p
技术落地与团队协作
FGS的规模化上线涉及多团队协作,包括视频算法、编码管线、基础设施、客户端兼容性等。设备认证和平台适配是主要挑战之一。Netflix已在部分支持设备上推送FGS流,用户可通过关闭HDR体验新效果。
FGS的推广不仅提升了流媒体的视觉表现,也为前端开发和UI设计带来更高的内容还原度和带宽利用效率。
9、WebAssembly, ‘Hyper VMs’ and Hypervisors: Fast Speeds, Intense Isolation(英文)

文章剖析了WebAssembly与Hyperlight结合带来的多层隔离安全优势及其在Envoy等场景下的集成挑战。Hyperlight通过硬件隔离强化Wasm沙箱,提升云端安全,但当前性能有待优化,未来将聚焦工具链完善与运行效率提升。
深度总结
WebAssembly与Hyperlight的结合:隔离性与性能的探索
WebAssembly(Wasm)和Hyperlight的结合,旨在实现更高层次的安全隔离和低延迟执行。Hyperlight是一种轻量级虚拟机管理器(VMM),可嵌入应用程序内部,专为在微型虚拟机(micro VM)中安全执行不受信任代码而设计。Wasm则通过软件层面的沙箱机制(Software-Fault Isolation, SFI)提供额外的安全保障。
多重隔离机制的实现方式
在实际应用中,Wasm沙箱运行在Hypervisor沙箱之内。以Envoy网络过滤器为例,应用程序首先创建一个Hyperlight Wasm沙箱,准备执行Envoy Network Filter的guest代码。数据处理时,主机调用guest进行计算,guest处理后再回调主机。这样,Wasm和Hypervisor的双重隔离机制共同作用,提升了整体安全性。
类型系统与数据交互
Hyperlight拥有丰富的类型系统,用于主机与guest之间的数据通信。开发者可以通过Protocol Buffers或FlatBuffers等工具进行序列化和反序列化,绕过底层类型系统的复杂性,灵活传递数据接口。
Rust实现与多线程挑战
Hyperlight完全用Rust编写。由于主机与guest之间需要双向调用,涉及Rust与C++的互操作,虽然需要一定的样板代码,但实现难度并不高。Hyperlight主机采用多线程模型,每个沙箱对应一个线程。这与Envoy的单线程、异步回调架构存在冲突,导致数据结构访问受限。为此,开发团队增加了回调重定向机制,确保所有回调都在Envoy的工作线程中执行,保证数据访问的正确性。
状态管理与call context
Hyperlight提供了call context机制,允许在多次guest函数调用间保持状态,直到显式调用“finish”重置状态。若不使用call context,每次guest调用结束后,所有状态都会被清空。这一特性对功能设计有直接影响,开发者需根据实际需求选择合适的状态管理方式。
性能基准与优化方向
性能测试以Echo函数为例,比较了Hyperlight Wasm、原生Hyperlight guest(不含Wasm)和Proxy-Wasm三种实现。结果显示,Hyperlight Wasm在每次调用后清理状态,带来较大开销;而原生实现可跳过此步骤,性能提升约15%。随着负载从128字节增加到4KB,延迟增长有限,说明系统开销主要来源于沙箱机制本身。近期的开发版本已在guest函数调用上实现了50%的性能提升。
未来发展与集成
Hyperlight团队正在开发Wasm的C API,便于集成到非Rust代码库。未来计划将Hyperlight Wasm作为Proxy-Wasm的引擎之一,进一步拓展其在Envoy等云原生场景下的应用。性能优化和可观测性工具的完善,将是后续工作的重点。Hyperlight通过硬件隔离与软件隔离的结合,为公有云等高安全需求场景提供了可插拔、易集成的微型虚拟机解决方案。
10、Building a Trend Detection System with AI in TypeScript: A Step-by-Step Guide(英文)

本项目用TypeScript和AI打造了一个自动化趋势检测系统,集成多API抓取与AI分析,自动推送结果到Slack。架构模块化、类型安全,支持Docker和GitHub Actions自动化,适合小团队高效监控多源趋势。
深度总结
项目概述
本文详细介绍了如何使用 TypeScript 和 AI 构建一个社交媒体趋势检测系统。该系统能够自动监控社交平台和新闻网站,分析新兴趋势,并通过 Slack 实时推送结果。项目采用模块化架构,强调类型安全、可扩展性和自动化部署。
技术栈与依赖
- Node.js:运行环境,要求 16 及以上版本。
- TypeScript:实现类型安全,提升代码健壮性。
- Firecrawl API:负责网页内容抓取,具备 AI 驱动的内容提取能力,能适应网页结构变化。
- X (Twitter) API:用于实时监控指定账号的推文和互动数据。
- Together AI:承担内容分析、趋势识别和摘要生成,支持情感分析。
- Slack Webhook:实现趋势推送通知。
- Zod:用于运行时数据结构校验,保证数据一致性。
- Docker:支持多阶段构建和环境隔离,便于部署和扩展。
- GitHub Actions:实现自动化定时任务和持续集成。
系统架构与核心流程
-
资源配置
通过.env文件集中管理 API 密钥和敏感配置。抓取源包括新闻网站和 X 账号,支持灵活扩展。系统会根据 API Key 的可用性动态筛选可抓取的源。 -
内容抓取
- 对于 X 账号,系统通过 API 拉取近 24 小时的推文,过滤掉转发和回复,仅保留原创内容。
- 对于网站,Firecrawl 结合自定义 prompt 和 Zod schema,提取当天与 AI/LLM 相关的新闻标题、链接和发布时间。所有数据结构都经过严格校验,确保后续处理的可靠性。
-
内容分析与摘要
利用 Together AI 的 Llama 3.1 模型,对抓取到的原始内容进行趋势提取和摘要。模型根据预设 schema 输出结构化 JSON,内容包括每条趋势的链接和一句话描述。系统会自动筛选出最具代表性的 10 条(如不足则全部输出)。 -
通知推送
通过 Slack Webhook,将最终生成的趋势摘要以消息形式推送到指定频道。推送内容包含日期、趋势描述及对应链接,便于团队成员快速获取关键信息。 -
自动化与部署
支持本地运行和 GitHub Actions 自动化。通过 GitHub Actions,可实现每日定时自动抓取、分析并推送,无需人工干预。所有敏感信息通过 GitHub Secrets 管理,保障安全。
关键特性与优势
- 模块化设计:各功能模块职责单一,便于维护和扩展。
- 类型安全:全流程 TypeScript + Zod 校验,降低运行时错误风险。
- 高可用性:Docker 支持多环境部署,GitHub Actions 实现自动化运维。
- 灵活配置:可随时调整监控主题、数据源和推送策略,适应不同业务需求。
- AI 驱动分析:结合 LLM 实现趋势识别和内容摘要,提升信息处理效率。
使用与扩展建议
- 可根据实际需求调整监控主题和数据源,支持多频道推送和多主题并行分析。
- 针对 API 限流和免费额度,建议合理规划抓取频率,必要时升级服务。
- 可进一步集成监控与告警机制,提升系统稳定性和可观测性。
局限性
- X API 免费版存在抓取频率限制,影响大规模账号监控。
- Together AI 免费额度有限,需关注用量。
- GitHub Actions 免费分钟数有限,适合中小规模自动化场景。
总结
该系统为趋势监控和信息推送提供了完整的自动化解决方案。通过模块化架构、类型安全和 AI 能力,能够高效、稳定地服务于团队的信息流需求。适合有一定开发基础、希望提升自动化和智能化水平的从业者参考和实践。
11、How JSDoc Saved My Dev Workflow(英文)
JSDoc 通过注释为 JavaScript 提供类型提示和错误检查,无需构建步骤,结合 VS Code 和 ESLint 插件,能有效恢复 TypeScript 式的开发体验,提升代码安全性和可维护性。
深度总结
JSDoc在开发流程中的实际价值
作者在项目开发中通常首选TypeScript,但在某些场景下,TypeScript并不适用。例如,项目体量极小、无法引入构建流程,或代码需要交由他人灵活修改时,TypeScript的编译步骤会成为负担。此时,开发者失去了类型检查、函数签名提示等便利,影响了代码的可维护性和安全性。
JSDoc的基本用法与优势
JSDoc是一种为JavaScript代码添加注释的方式。通过特定格式的注释,开发者可以描述函数、参数和返回值。JSDoc的注释不会影响代码执行,也无需额外的构建步骤。编辑器能够识别这些注释,提供类型推断、参数提示等功能,提升开发体验。
TypeScript与JSDoc的协同
TypeScript编译器支持JSDoc注释。只需在JavaScript文件顶部添加 // @ts-check,或在项目根目录配置jsconfig.json并启用checkJs选项,便可获得类型检查能力。这样,开发者无需将项目完全迁移到TypeScript,也能享受类型系统带来的安全性。
ESLint与JSDoc的结合
通过配置ESLint并集成JSDoc插件,可以对注释的规范性和类型标注进行静态检查。这样不仅能捕捉潜在的类型错误,还能保证文档注释的准确性。实际应用中,作者通过这种方式发现了多处隐藏的代码缺陷。
结论
JSDoc为无法使用TypeScript的场景提供了类型安全和文档维护的解决方案。结合TypeScript和ESLint工具链,开发者能够在不引入复杂构建流程的前提下,提升代码质量和开发效率。
推荐阅读
1、8个技巧解锁Claude Code的上限,打造最强的AI编程工具(中文)
Claude Code通过多开、权限绕过、魔法词ultrathink、MCP插件和Token监控等技巧,极大释放AI编程潜力,适合有基础的开发者深度协同使用,显著提升效率与价值。
深度总结
Claude Code高效使用技巧总结
本文系统梳理了Claude Code在实际开发中的高阶用法,重点关注与IDE协同、权限管理、多实例并行、Token消耗监控、思考深度控制、MCP插件扩展以及历史记录管理等方面。内容针对有一定开发经验的从业者,强调实用性和操作细节。
1. 与IDE协同工作
通过在Cursor或VS Code中安装Anthropic官方插件,Claude Code可直接嵌入IDE,实现文件编辑、修改预览等功能。插件安装后,IDE界面会出现Claude Code图标,点击后可在编辑区直接调用Claude Code。此时,Claude Code与IDE处于“IDE connected”状态,能够自动同步文件变更,提升开发效率。例如,开发者在Cursor中修改代码,Claude Code可实时预览并协助修正。
2. 多实例并行处理
支持同时开启多个Claude Code实例,适用于需要并行处理多个任务的场景。每个实例可独立执行任务,但只有最后打开的实例与IDE保持协同。建议有经验的开发者在不同项目间使用多实例,避免多个实例同时修改同一文件导致冲突。对于初学者,建议先单实例操作,逐步熟悉流程。
3. 权限管理与Bypassing Permissions
为避免Claude Code在执行过程中频繁请求授权,可通过命令行参数--dangerously-skip-permissions一键授予所有权限。可设置alias简化操作流程。例如,将claude命令映射为claude --dangerously-skip-permissions,实现自动跳过权限校验,减少中断。
4. Token消耗监控
通过安装ccusage库,开发者可实时监控Claude Code的Token消耗情况。命令行工具支持查看历史消耗、指定日期区间统计以及实时监控。此功能有助于成本控制和资源分配。例如,输入ccusage blocks --live可实时查看API Token的消耗速率。
5. 控制思考深度:ultrathink
Claude Code支持通过“魔法词”调整思考深度。以“ultrathink”为例,输入后可显著提升Claude Code的推理和生成能力,适合处理复杂任务。该机制通过消耗更多Token换取更高质量的输出。开发者可根据任务复杂度灵活选择“think”、“think hard”、“think harder”或“ultrathink”。
6. MCP插件扩展
context7和browsermcp是推荐安装的MCP插件。context7可补充大模型知识库的时效性,自动引入最新代码库信息。browsermcp允许Claude Code直接操作浏览器,辅助开发者检索和分析网页内容。例如,可自动打开小红书并抓取内容进行总结,提升界面和交互开发效率。
7. 历史记录管理
通过/resume命令,开发者可快速查看和检索历史对话记录,并选择继续某一会话。该功能便于追踪任务进展和复用先前的讨论内容。
8. Claude Code与Cursor的定位差异
Cursor强调与开发者的协作和启发,适合频繁交互。Claude Code更像编程实习生,适合有明确需求和一定编程基础的用户。建议初学者先通过Cursor或AugmentCode打好基础,再逐步引入Claude Code以提升自动化和批量处理能力。
2、2025,10000个Vibe Coding井喷(中文)
2025年,AI编程工具井喷,推动开发者从“写代码”转向“审代码”与创意主导。主流产品实现了从自然语言到应用的自动生成,自动化水平持续提升,AI正成为软件开发的核心力量,重塑行业格局。
深度总结
2025年AI编程工具的爆发与演进
2025年,AI编程工具迎来爆发式增长。主流大厂和创业团队纷纷推出创新产品,推动“AI Coding”成为开发者社区的核心话题。AI工具已不再局限于代码补全,而是能够理解需求、规划任务、甚至独立完成应用开发。开发者的角色正从“写代码”转向“审代码”,并参与更具创造性的工作。
主要AI编程工具概览
- 字节-Trae:以Builder模式重塑开发流程,支持自然语言需求拆解、文件结构生成和代码实现。集成多种大模型,强调与设计工具的无缝衔接。
- 阿里-通义灵码(Lingma IDE):深度集成Qwen3模型,构建智能开发生态,插件下载量和代码生成量均居前列。
- 美团-Nocode:主打“Vibe Coding”,通过多轮对话生成可部署应用,强化协同编辑和后端能力。
- 百度-Zulu/秒哒:Zulu面向专业开发者,支持多模态输入和全栈自动化开发。秒哒则服务非技术用户,实现零代码开发。
- YouWare:降低网页实现门槛,适合技术小白和老手,强调社区和激励机制。
- AIGCode:Autocoder实现端到端软件生成,推动个性化应用生态。
- Clacky AI:云端开发环境,支持多主流开发栈,具备结构化任务拆解和自我修复能力。
- Cursor:开源友好型代码编辑器,支持多模型驱动和终端内AI对话,提升全栈开发效率。
- Windsurf:专注复杂系统重构,具备全代码库动态索引和级联影响分析能力。
- Codex:支持180多种编程语言,擅长复杂逻辑生成。
- Claude Code:命令行智能编程工具,支持自然语言操作代码库和自动化测试。
- Google Code Assist:基于Gemini模型,支持多语言编程和大容量上下文处理。
- v0:专注前端UI生成,通过自然语言快速生成React组件。
- Lovable:对话式无代码开发平台,强调自然语言建站,非技术用户占比高。
- Bolt.new:极速建站生成器,自动生成前后端及部署脚本。
- MGX (MetaGPT-X):多智能体协作,实现全流程自动化开发。
AI编程工具的两种形态
AI编程工具主要分为IDE形态和对话形态。
- IDE形态(如Trae、Cursor、Lingma):采用三栏结构,左侧为资源管理器和导航,中央为代码编辑区,右侧为AI对话栏。熟悉的界面降低上手难度,提升效率。支持在编辑器和终端内与AI交互,部分产品支持自定义模型接入。
- 对话形态(如NoCode、Lovable):界面极简,核心为对话框。用户通过自然语言描述需求,AI自动生成和部署应用。项目页面通常左侧展示需求结构,右侧为实时预览。部分平台支持项目协作和版本管理。
交互与体验差异
IDE类产品强调专业性和流程规范,适合有开发经验的用户。对话类产品则降低技术门槛,适合希望快速实现想法的用户。两类产品在需求输入、代码生成、项目修改等环节的交互方式存在明显差异。例如,Cursor支持在终端直接与AI对话,而NoCode更注重全权委托和自动化输出。
自动化能力分级
AI编程工具可借鉴自动驾驶的分级体系,从L1到L5:
- L1:代码补全(如Tabnine、Kite)。
- L2:任务自动化,支持自然语言生成代码(如ChatGPT、Claude)。
- L2.5/原生AI IDE:AI能力直接融入IDE,支持上下文理解和代码直接运行(如Trae)。
- L3:项目级自动化,从需求到部署部分自动化(如Claude Code)。
- L4-L5:全流程自动化,部分产品处于内测或概念阶段(如MetaGPT、Lovable)。
结论
AI编程工具正推动开发范式转变。无论是专业开发者还是非技术用户,都能借助AI实现更高效的项目开发和创新。未来,AI在编程领域的作用将持续增强,开发者的工作内容和方式也将随之演变。
3、微信技术架构部斩获CVPR 2025大赛冠军,攻克AI图文匹配评估难题(中文)

腾讯微信IH-VQA团队以iMatch创新方案在CVPR 2025图文匹配评估赛道夺冠,通过双模型融合、数据增强和概率映射等多项技术创新,刷新了行业评测基准,并推动了T2I模型评测体系的完善,彰显了其在AI多模态质量评估领域的技术引领力。
深度总结
微信技术架构部在CVPR 2025大赛中的突破
微信技术架构部的IH-VQA团队在CVPR 2025 NTIRE “Text to Image Generation Model Quality Assessment - Track 1 Image-Text Alignment”挑战赛中获得冠军。他们提出的iMatch图文匹配质量评估方案,成为AI领域图文匹配质量算法研究的创新标杆。该方案不仅提升了AI生成模型的评估精度,也为后续模型优化提供了明确方向。
任务背景与挑战
近年来,Text-to-Image(T2I)模型如Dreamina、DALL·E3、Midjourney等快速发展。这些模型能够根据用户的prompt生成高质量图像。随着T2I技术普及,如何科学评估模型生成图像与文本描述的匹配度、美学和结构完整性成为难题。传统评估方法难以全面衡量图文匹配度,尤其在多模态大模型的结构理解方面存在短板。
赛事数据与评测标准
本次比赛采用EvalMuse数据集,包含4万组image-text pairs,由20个主流T2I模型基于4千条多样化prompt生成。评测分为主评分(Main Score)和元素级评分(Element Score),分别用SRCC(斯皮尔曼等级相关系数)、PLCC(皮尔逊线性相关系数)和ACC(准确率)衡量模型的预测单调性、准确性和元素描述的正确率。最终排名结合上述三项指标。
iMatch方案的核心创新
-
双模型驱动与分数融合
团队针对PS(主评分)和ACC(元素级评分)分别训练模型,并通过分数融合提升整体表现。例如,某模型在PS上表现优异,另一个在ACC上更强,通过组合两者优势获得更高总分。 -
伪标签数据增强
利用初赛阶段测试集,通过表现最佳模型生成伪标签,将部分数据混入训练集,提升模型对细节的学习能力。这种方法有效扩展了训练数据的多样性。 -
Q-Align概率映射策略
借鉴VQA领域Q-Align方法,将评分级别与分数映射,采用概率加权生成连续分数。该策略提升了模型对人类评分标准的拟合能力。 -
视觉数据增强
针对T2I任务特点,采用亮度调整、轻微形变和裁剪等方式增强图像数据。避免旋转增强,因为许多prompt包含位置描述(如left、right等),旋转会破坏语义一致性。
评测与行业影响
IH-VQA团队在SRCC、PLCC、ACC三项核心指标上均领先第二名,刷新了领域性能基准。团队的技术方案被CVPR 2025 Workshop收录,并在会议现场做Oral Presentation。此次胜利也标志着腾讯WXG在音视频质量算法领域的持续领先。
iMatch Benchmark与模型评测
团队基于iMatch框架,构建了包含23个T2I模型的评测集,覆盖多种分辨率(512×512、768×768、1024×1024)。评测显示,字节跳动的seedream-3.0和智象未来的HIDREAM模型在细粒度图文匹配能力上表现突出。HIDREAM在不同分辨率下均取得最高分,尤其在768×768分辨率下优势明显。
未来展望
团队将继续专注于多模态质量评价和实时质量监测等关键技术,推动AI在复杂场景下的图文与音视频质量评估能力提升,为内容生态建设提供更精准的技术保障。
4、从输入指令到代码落地:Cline AI 源码浅析(中文)

Cline AI通过将用户指令、环境信息和文件内容高度集成,结合模型定制化prompt和自动化工具调用,实现了自然语言到代码落地的高效闭环,极大提升了开发效率和智能化水平。
深度总结
Cline AI 源码流程解析
本页内容详细剖析了 Cline AI 如何将自然语言指令转化为具体的编程任务,并最终实现代码的自动生成与修改。文章以源码为切入点,逐步揭示了从用户输入到代码落地的完整流程。
启动与调试流程
Cline 的本地开发环境依赖于 VSCode 插件。开发者需克隆仓库,安装依赖,并在 VSCode 中启动调试。调试过程中,Webview 负责收集用户输入,而实际的任务处理逻辑则由 VSCode 主进程承担。Webview 与主进程通过消息机制进行通信,确保输入信息能够被准确传递和处理。
指令输入与消息传递
用户通过输入框提交自然语言指令,例如“/newtask 实现快速排序算法,写入 @/src/utils/index.ts 文件”。Cline 支持内置命令(如 /newtask)和 @ 功能,允许用户指定操作文件或目录。Webview 收集输入后,将其封装为消息,通过 postMessage 发送至主进程。
主进程任务初始化
主进程接收到消息后,进入任务初始化阶段。核心逻辑集中在 Task 类的实例化。Task 类负责管理任务的上下文、历史记录、API 配置等。初始化完成后,系统会根据用户配置选择合适的 AI 模型,并构建 API handler。
Prompt 组装与上下文构建
Cline 在构建 prompt 时,融合了多种上下文信息,包括:
- System Prompt:定义可用工具及其调用方式。例如,replace_in_file 工具用于精确修改文件内容,要求严格匹配和替换。
- 用户输入:原始指令被包装为 task 标签。
- 文件内容:如用户指定了文件,系统会读取并纳入上下文。
- 环境信息:如当前工作目录、时间、打开的 Tab 等。
这些信息共同组装为完整的 prompt,发送给模型,确保模型具备足够的上下文以生成准确的响应。
模型请求与工具调用
模型收到 prompt 后,生成响应内容。响应中可能包含工具调用指令(如 <replace_in_file>),指示系统对指定文件进行修改。Cline 解析模型输出,识别所需工具及参数,并调用相应工具执行操作。以快速排序算法为例,模型会在指定文件末尾插入实现代码,并通过 diffView 展示变更。
关键技术要点
- Prompt 组装:多维度上下文融合,提升模型理解与生成能力。
- 工具调用:通过 System Prompt 明确工具接口,模型输出直接驱动自动化操作。
- 用户体验:任务执行过程实时反馈,代码变更以可视化 diff 形式呈现,便于用户审查。
Agent 开发的核心
Cline 的实现强调三点:最大化模型价值、丰富的应用场景、流畅的用户体验。通过精细的 prompt 设计和工具集成,Cline 实现了自然语言到代码的高效转化,为开发者提供了强有力的智能助手。
5、为什么 DeepSeek 大规模部署很便宜,本地很贵(中文)
DeepSeek等大模型依赖批处理推理提升GPU利用率,大规模部署时能以低成本高效率服务众多用户,但本地单用户场景下因缺乏并发,批处理难以实现,导致推理效率低、成本高,难以高效个人部署。
深度总结
DeepSeek大规模部署为何便宜,本地推理为何昂贵
DeepSeek-V3等大模型在大规模服务时表现出高效且低成本,但在本地单用户环境下推理则变得缓慢且昂贵。根本原因在于推理服务的吞吐量与延迟之间的权衡,以及批处理机制对GPU利用率的影响。
批处理推理的原理
GPU擅长执行大型矩阵乘法(GEMM)。在推理过程中,将多个token堆叠成一个大矩阵进行一次乘法,远比多次小规模乘法高效。例如,128个token可以组成128x模型维度的矩阵,GPU一次性处理,极大提升吞吐量。推理服务器会将来自不同用户的请求排队,形成批次,批量送入GPU处理。批次越大,GPU利用率越高,但用户等待时间(延迟)也随之增加。
吞吐量与延迟的权衡
批处理大小直接影响吞吐量和延迟。小批次意味着低延迟,但GPU利用率低,整体吞吐量下降。大批次则提升吞吐量,但用户需等待批次填满,延迟上升。推理服务提供商通常会根据实际需求设定一个“收集窗口”,在窗口内收集请求,批量处理。
专家混合模型的特殊需求
DeepSeek-V3采用专家混合(Mixture of Experts, MoE)架构。模型包含多个“专家”,每个token只经过部分专家。此结构导致每个专家实际处理的token数量较少,若批次不够大,GPU执行的矩阵乘法规模小,效率低下。只有在高并发、大批次场景下,所有专家才能被充分利用,提升整体吞吐量。
管道化与管道气泡
大型模型通常采用管道化,将不同层分布在多块GPU上。推理时,token按顺序通过各层。若批次过小,部分GPU会因等待数据而空闲,形成“管道气泡”,进一步降低效率。为避免这种情况,推理服务会设定较大的批次,确保每个tick(批次处理周期)内有足够的token流经所有层。
本地推理的局限
个人用户本地运行模型时,通常只有单个请求,无法形成大批次。GPU只能处理小规模矩阵乘法,利用率极低,推理速度慢且成本高。相比之下,云端服务通过聚合大量用户请求,批量推理,显著提升效率并摊薄成本。
架构差异与服务策略
OpenAI、Anthropic等厂商的模型响应速度较快,可能源于更高效的模型架构(如非MoE、层数更少),或采用了更先进的推理调度技术,也可能是通过增加GPU资源来降低延迟。
结论
大规模推理服务通过批处理机制和高并发流量,显著提升了GPU利用率,降低了单位推理成本。专家混合模型和深层管道模型对批次大小要求更高,导致本地单用户推理效率极低。推理服务提供商需在吞吐量和延迟之间做出权衡,选择合适的批处理策略以满足不同场景需求。
AI Agent通过“LLM+记忆+规划+工具”架构,实现了从对话生成到自主执行的飞跃。多Agent协作、标准化工具调用和灵活的思考模式,使其能高效处理复杂任务,推动AI成为真正的智能代理,极大拓展了前端与AI的结合空间。
深度总结
AI Agent:前端视角下的智能执行者
AI Agent的出现,标志着AI系统从“对话”向“行动”转变。传统的大型语言模型(LLM)擅长生成内容和对话,但在处理需要实时信息和复杂操作的任务时,能力有限。例如,用户请求一份结合实时天气的旅行计划,LLM只能基于历史数据给出泛泛建议,无法满足实际需求。
AI Agent的核心构成
AI Agent的本质可以用一个公式概括:
AI Agent = LLM(大脑) + Memory(记忆) + Planning(规划) + Tools(工具)
- LLM:负责理解用户意图、推理和决策,相当于系统的“大脑”。
- Planning:将复杂任务拆解为可执行的步骤。例如,规划旅行时,先查天气,再查酒店,最后安排行程。
- Memory:记录历史交互和中间结果,保证多轮对话和长期任务的上下文连贯。
- Tools:通过API、数据库等方式与外部世界交互,实现信息查询和操作。
多Agent协作架构
实际项目中,AI Agent通常采用多Agent协作模式。每个Agent专注于特定领域,提升系统的专业性和可扩展性。以智能旅行规划助手为例,系统包含:
- AnalyzerAgent:解析用户需求,提取目的地、时间、预算等信息。
- WeatherAgent:查询实时天气,提供出行建议。
- PlannerAgent:结合需求和天气,生成详细行程。
这些Agent由AgentCoordinator统一调度,确保信息流转和任务分配有序。
工具调用与Function Calling
AI Agent通过Function Calling机制调用外部工具。开发者定义函数及其参数描述,LLM在推理过程中决定何时调用哪个工具。模型不会直接执行操作,而是生成调用指令,由系统解析并执行,再将结果反馈给模型。这样,LLM能够动态获取实时数据或执行操作,突破知识库的时效性限制。
MCP与A2A协议
随着需求复杂化,工具调用正向MCP(Model Context Protocol)等标准化协议演进。MCP采用Client-Server架构,支持本地和远程部署,基于JSON-RPC 2.0协议通信。A2A协议则专注于Agent间数据交换,提升多团队协作效率,减少格式不一致带来的沟通成本。
AI Agent的思考模式
AI Agent的自主性依赖于LLM的推理和规划能力。主流有两种模式:
- Plan-and-Execute:先整体规划,再分步执行。适合流程明确、步骤依赖性强的任务。
- ReAct:推理与行动交替进行。每完成一步,观察结果,再决定下一步。适合需要动态调整的场景。
两种模式可以结合使用,提升系统灵活性和鲁棒性。
前端开发者的角色
AI Agent的实现高度依赖于前端技术。无论是工具调用、数据可视化,还是多Agent协作流程的编排,前端开发者都能发挥关键作用。主流SDK和框架普遍支持JS/TS,降低了前端与AI应用的技术门槛。
结语
AI Agent推动了AI系统从信息提供者向智能执行者的转变。通过多Agent协作、标准化协议和灵活的思考模式,AI Agent能够处理更复杂、更贴近实际需求的任务。前端开发者在这一变革中具备天然优势,值得持续关注和深入探索。
本文系统梳理了Vue3开发中提升性能与开发效率的10大实用技巧,涵盖响应式优化、数据解包、DOM监听、列表渲染、逻辑复用、页面体验、组件内容管理、表单处理、组件缓存及多线程处理,助力开发者高效应对复杂项目挑战。
深度总结
1. shallowRef 与 shallowReactive:优化大型数据的响应式性能
Vue3 默认的深度响应式在处理大规模数据时会导致性能瓶颈。shallowRef 只对基本数据类型的直接赋值做响应,shallowReactive 只追踪对象的顶层属性变化。实际案例中,使用 shallowReactive 管理上万条数据的表格,页面流畅度显著提升。对于大数据场景,优先考虑这两种“浅层”响应式方案。
2. toRef 与 toRefs:高效解包响应式对象
直接从响应式对象中取值容易导致响应失效。toRef 可单独提取某个属性并保持响应式,toRefs 可一次性提取多个属性。这样既减少了重复代码,也保证了数据的响应性。例如,使用 toRefs 解包 product 对象后,修改 price 或 stock 会同步反映到原对象。
3. watchPostEffect:确保数据监听在 DOM 更新后执行
watchPostEffect 的回调会在组件 DOM 更新完成后执行,适用于依赖最新 DOM 状态的场景,如动态计算元素位置或初始化第三方插件。它能有效避免回调执行早于数据准备好的问题。
4. v-for 的 key:提升列表渲染的准确性和性能
在 v-for 渲染列表时,设置唯一的 key 能帮助 Vue 快速识别每个列表项,避免数据错乱和渲染性能下降。key 的存在让 Vue 能高效地进行增删改查操作。
5. 自定义 Hooks:提升代码复用性
将表单验证、数据请求等重复逻辑封装为自定义 Hooks,可以极大提升开发效率和代码可维护性。Hooks 应保持通用性,避免过度复杂化。
6. v-cloak:防止页面初始渲染时的内容闪烁
v-cloak 配合 CSS 可在 Vue 实例挂载前隐藏带有 v-cloak 属性的元素,避免用户看到未渲染的模板插值。数据渲染完成后,v-cloak 自动移除,内容正常显示。
7. v-slot:灵活的组件内容分发
v-slot 支持具名插槽和作用域插槽,允许父组件灵活传递和展示内容。通过作用域插槽,父组件可以获取子组件传递的数据,实现高度自定义的内容渲染。
8. v-model 的修饰符:简化表单输入处理
v-model 提供 .number、.trim、.lazy 等修饰符,分别用于将输入值转为数字、去除首尾空格、延迟数据更新。这些修饰符简化了表单数据的预处理逻辑。
9. keep-alive:缓存组件状态,优化切换性能
keep-alive 能缓存被包裹组件的状态,适用于 tabs、导航等频繁切换的场景。组件切换时不会被销毁,状态得以保留,显著提升用户体验和性能。
10. Web Workers:多线程处理复杂计算
Web Workers 可将耗时计算任务(如大数据排序、加密)放到后台线程执行,避免阻塞主线程,保证页面流畅。Vue3 项目中合理利用 Web Workers,有助于解决性能瓶颈。
总结
上述十个技巧涵盖了数据响应、性能优化、组件开发和多线程处理等多个方面。合理运用这些方法,可以有效提升 Vue3 项目的开发效率和用户体验。
8、<img> 标签最强攻略:性能、SEO、可访问性一篇全懂(中文)
本文系统梳理了HTML <img>标签的核心用法与优化技巧,涵盖属性配置、性能提升、SEO与可访问性、响应式图片、跨域与隐私控制等关键点,强调合理使用属性和现代技术是高效网页图片体验的基础。
深度总结
基础用法
<img>标签用于在网页中嵌入图片。它是自闭合标签,必须包含src属性,推荐始终添加alt属性。src指定图片路径,可以是相对路径、绝对路径或完整URL。alt为图片提供替代文本,提升SEO和可访问性。
关键属性解析
- src:定义图片资源地址。路径类型影响加载速度、跨域策略和缓存。相对路径适用于本地资源,绝对路径以网站根目录为起点,完整URL常用于CDN或第三方资源。
- alt:为图片提供简洁、准确的描述。图片无法加载时显示,屏幕阅读器辅助访问,提升SEO。
- width/height:指定图片显示尺寸,单位为像素。提前分配空间,防止页面布局抖动(CLS),提升渲染性能。
- loading:控制图片加载时机。
lazy实现懒加载,非首屏图片进入视口时才加载,提升首屏性能。首屏图片建议优先加载。 - decoding:控制图片解码方式。
async为异步解码,不阻塞主线程,适合大图和非关键图片。sync为同步解码,适合需要立即显示的关键图片。 - srcset/sizes:实现响应式图片。浏览器根据设备分辨率和屏幕宽度动态加载最优资源,节省流量,提升清晰度。
- crossorigin:控制跨域请求策略。
anonymous不带凭证,适用于公开资源。use-credentials带凭证,适用于需要认证的图片资源。服务器需正确配置Access-Control-Allow-Credentials和Access-Control-Allow-Origin。 - referrerpolicy:控制图片请求时的
Referer头部。可隐藏或修改请求来源,保护隐私或配合防盗链策略。常用值如no-referrer、origin、strict-origin等。 - usemap/ismap:实现图片热点链接和坐标传递。
usemap结合<map>标签定义可点击区域,ismap配合<a>标签传递点击坐标。
性能优化实践
结合懒加载、CDN分发、WebP格式压缩等技术提升图片加载效率。为非首屏图片加loading="lazy",合理使用srcset和sizes,移动端优先加载小图,桌面端加载大图。图片尽量压缩,避免使用base64大图。
SEO与可访问性
alt属性必填,准确描述图片内容。装饰性图片可用alt="",让屏幕阅读器跳过。图片应与页面内容相关,配合标题和描述提升语义。
最佳实践
始终为图片指定alt、width、height。合理配置loading、decoding、srcset、sizes等属性。结合现代框架自动优化图片。避免滥用大图和忽略alt属性,提升加载速度和可访问性。
结语
合理使用<img>标签及其属性,关注性能、SEO和可访问性,是前端开发的基本功。结合响应式、懒加载、CDN、WebP等技术,能够显著提升用户体验和页面表现。
9、写了几年React,我只想说:“它现在真的疯了”(中文)
本文以作者亲身经历为线索,剖析了 React 从简洁到复杂的演变过程,指出其组件化和 Hooks 机制虽带来灵活性,却也导致项目结构碎片化、状态管理混乱,开发体验大幅下降。作者认为,Web UI 的交互本质极其复杂,任何技术栈都难以彻底解决。最终建议回归服务器端渲染,仅在必要处引入前端交互库,以“交互小岛”模式简化开发,提升可维护性。
深度总结
React的复杂性与前端架构的演变
React曾以其简洁和灵活的组件化理念成为Web开发的主流选择。然而,随着时间推移,React及其生态逐渐变得复杂,许多开发者开始质疑其“简单”的本质。本文作者结合自身经历,梳理了前端框架从Angular到React的演变过程,并深入分析了React在状态管理、架构设计、Hooks等方面带来的实际困扰。
从Angular到React:框架与库的分野
早期的Angular.JS为Web开发带来了结构化和范式化的变革。它通过组件化(directives)和双向绑定,极大简化了大型应用的开发。相比之下,jQuery更像是对DOM API的包装,适合小型项目,但在复杂场景下难以维护。Angular的出现让开发者能够专注于UI和业务逻辑,而不必手动操作HTML。
随着需求的提升,Angular 2的重写带来了更高的复杂度。React则以“库”自居,强调极简主义。它本身只关注UI层,其他功能需依赖外部库补充。这种“自带啤酒”哲学导致每个React项目都像是拼装而成,缺乏统一标准,增加了维护难度。
组件式架构与状态管理的困境
React推崇组件式架构,应用由自顶向下的组件树构成。理论上,状态应自上而下传递。但实际开发中,组件数量庞大,状态传递变得繁琐。React Hooks的引入允许状态在任意组件中“旁加载”,但这本质上类似全局变量,增加了代码不可控性。reducer等模式虽有工程化包装,但难以彻底解决状态管理的混乱。
Hooks与副作用的复杂性
Hooks,尤其是useEffect,带来了副作用管理的新方式。理想情况下,副作用应与核心逻辑分离。但在实际开发中,useEffect常被用作组件初始化,甚至管理状态。这导致副作用与状态更新交织,代码执行顺序难以直观理解。多个useEffect嵌套时,依赖关系和执行顺序变得晦涩,增加了认知负担。
“最佳实践”与复杂性的悖论
React社区推崇的“最佳实践”模式,往往为了解决简单问题引入了复杂的设计。例如,仅为渲染一个列表,可能需要多层抽象和高认知成本。CSS-in-JS等方案进一步加剧了复杂性。虽然JSX打破了“关注点分离即文件分离”的观念,但将CSS也纳入JSX,反而让代码维护变得更加困难。
复杂性的根源与反思
作者认为,Web UI的本质复杂性远超传统系统。任意组件间的交互和状态影响,使得代码难以保持简洁。无论选择何种技术栈,最终都要面对交互式UI带来的工程挑战。许多Web应用其实并不需要SPA架构,服务端渲染往往能带来更低的复杂度和更高的可维护性。
可能的出路:减法思维与“交互小岛”
减少输入输出的数量是降低复杂度的有效手段。功能越少,代码越简单,维护越容易。服务端渲染可以将输出简化为单一页面,极大降低前端状态管理的需求。对于必须的交互,可以采用“islands of interactivity”模式,仅在局部引入React或其他库。这种方式有助于控制复杂性,提升开发效率。
结语
React的复杂性并非其自身的缺陷,而是交互式Web应用本身的工程难题。开发者应根据实际需求选择合适的架构,避免盲目追求前端技术的“全能化”,以减法思维应对复杂性挑战。
携程火车票团队创新性地提出图贪心分流算法,通过分层抽样、贪心优化和社区发现,有效解决了非用户端AB实验中分流不均和流量交叉问题,显著提升了分流效率和实验独立性,已在实际业务中取得优异效果。
深度总结
背景与问题
AB实验是互联网行业评估策略效果的标准方法。传统做法以用户为分流单位,通过哈希或随机分配实现实验组与对照组的均衡。随着业务复杂化,出现了以商品、商户等非用户实体为分流对象的需求。例如,电商平台需对商品优惠策略进行实验,或酒店平台对商户营销活动进行分流。这类场景下,实体数量较少、特征分布集中,且实体间存在关联,导致直接哈希分流会出现分组不均、流量交叉等问题。
非用户端分流的挑战
-
分流不均衡
非用户实体如商品、商户,特征稳定且分布单一。直接随机分流容易导致实验组与对照组在关键指标上出现系统性偏差。例如,高单价商品集中在一组,会影响GMV等指标的实验结论。 -
分流稳定性要求高
非用户端实验通常要求实验组和对照组在实验期间保持固定,避免策略切换带来干扰。因此,需在实验前进行“预分流”,并保证分流结果在历史和实验期间都具备相似性。 -
流量交叉问题
非用户实体间存在多对多关联。例如,用户可能同时浏览“鼠标”和“鼠标垫”,若两者分属不同组且被同一用户看到,会影响实验独立性。需尽量减少用户同时暴露于实验组和对照组的情况。
分流算法设计
为解决上述问题,携程火车票团队提出了结合随机抽样、贪心算法和图算法的分流方案。该方案包含三个核心模块:
-
分区随机抽样
通过分层抽样生成初始分组,确保各分组在分组变量(如类目、价格区间)下的指标分布接近。具体做法是将实体按分组变量划分为子层,排序后等距分桶,再跨子层组合生成候选分组,反复抽样直至满足指标差异要求。 -
贪心交换算法
在初始分组基础上,局部交换实验组与对照组的样本,逐步缩小各指标的最大相对差异。交换仅在同一分组变量下进行,保证分区均衡性。迭代终止条件包括达到指标差异阈值、陷入局部最优或达到最大迭代次数。 -
图的社区发现算法
针对流量交叉问题,引入社区发现算法(如Louvain)。以用户-实体的历史交互数据构建加权图,将高频共现的实体聚为社区。社区整体分配到实验组或对照组,最大限度减少用户跨组暴露。社区特征通过聚合原始实体特征获得,后续分流仍采用贪心交换。
实证分析与效果
在实际业务场景(如酒店商户营销策略实验)中,团队对比了三种分流方式:
- 图贪心分流(新方法)
- 基于先验知识的贪心分流(如按商业区打包)
- 基于先验知识的随机分流
评估维度包括流量交叉(模块度、用户交叉率)和分流精度(最大相对差异、AA校验通过率)。结果显示,图贪心分流在不降低分流精度的前提下,显著提升了分流通过率和模块度,并将用户交叉率从60%降至40%。贪心交换算法本身已大幅提升分流效率,图算法进一步优化了流量隔离和分流稳定性。
未来方向
团队提出,后续可进一步探索uv数据的图建模方式、图算法与贪心算法的效率平衡,以及分流精度、流量交叉、分区均匀性的权衡与平台化部署。
11、Deno 2.4: deno bundle is back(英文)

Deno 2.4 全面升级打包、资源导入、依赖管理、权限控制、Node 兼容、格式化等核心能力,极大提升了开发效率和生态兼容性,进一步巩固了其现代 JavaScript/TypeScript 运行时的领先地位。
深度总结
deno bundle 回归
Deno 2.4 恢复了 deno bundle 子命令。开发者可以将 JavaScript 或 TypeScript 项目打包为单一文件,适用于服务端和浏览器环境。该命令支持 npm 与 JSR 依赖,自动进行 tree shaking 和代码压缩,底层集成 esbuild。未来将开放 API 以便程序化调用,并计划支持插件机制,允许自定义打包流程。
原生支持文本与字节文件导入
通过 --unstable-raw-imports,可以直接在模块中导入文本或二进制文件。例如,导入 PNG 图片或 TXT 文件时,无需手动文件读取,资源会被打包进最终产物。这一特性同样适用于 deno compile,可将资源嵌入二进制文件。与以往 Next.js 等框架的实现不同,Deno 避免了 DSL 和预编译器带来的复杂性,尽量贴近标准规范。
OpenTelemetry 稳定
内置 OpenTelemetry 现已稳定,无需 --unstable-otel。只需设置环境变量 OTEL_DENO=1,即可自动采集日志、指标和追踪信息。日志会自动与 HTTP 请求关联,Node 环境下无需额外配置。
新增 —preload 标志
--preload 允许在主脚本执行前加载并运行指定代码。适用于修改全局变量、预加载数据、连接数据库等场景。该标志可用于 deno run、deno test 和 deno bench。
deno update 简化依赖管理
deno update 子命令可一键升级 deno.json 或 package.json 中的 npm 和 JSR 依赖。支持忽略 semver 限制、按包名过滤、递归更新等功能。该命令是 deno outdated --update 的简化别名。
deno run —coverage 支持主进程覆盖率采集
deno run 新增 --coverage,可在运行主进程时采集覆盖率,解决子进程测试覆盖率不全的问题。覆盖率报告支持 Markdown 格式,便于文档集成,并新增暗色模式。
DENO_COMPAT=1 环境变量
设置 DENO_COMPAT=1,可自动启用多项兼容 Node.js 的标志,简化 package.json 项目迁移。--unstable-sloppy-imports 现已稳定为 --sloppy-imports,允许省略文件扩展名的导入。
权限系统增强
--allow-net 现支持子域名通配符和 CIDR 范围。新增 --deny-import,可显式禁止从特定主机导入代码。Deno.permissions API 增加对 “import” 类型的支持。Deno.execPath() 不再需要读取权限,提升安全性和易用性。
npm 包条件导出
支持 npm 包的 conditional exports,可根据不同条件导出不同模块。例如,React 生态可通过 --conditions=react-server 切换 Server Components 导出。
deno run 支持 bare specifier 作为入口
deno run 现可直接使用 deno.json 中的 bare specifier 作为入口,无需指定完整路径,提升开发体验。
deno fmt 支持 XML 和 SVG
deno fmt 现可自动格式化 .xml 和 .svg 文件。.mustache 模板格式化需开启 --unstable-component。
tsconfig.json 支持增强
自动发现并支持 tsconfig.json,包括 "references"、"extends"、"files"、"include"、"exclude" 等选项。提升与主流前端框架(如 Vue、Svelte、Solid、Qwik)的兼容性。
Node.js 全局变量与 API 支持提升
Buffer、global、setImmediate、clearImmediate 等 Node.js 全局变量现对用户代码开放,无需额外标志。Node 相关模块兼容性提升,glob API 新增支持,@types/node 默认升级至 22.15.14。
其他改进
fetch支持 Unix 和 Vsock socket。deno serve支持onListen()回调。deno jupyter增强 Jupyter kernel 管理。- Lint 插件可访问注释节点。
deno bench和deno coverage表格兼容 Markdown。- Windows 下 Ctrl+Close(SIGHUP)信号监听修复。
结语
Deno 2.4 带来大量功能增强和开发体验优化,涵盖打包、依赖管理、权限控制、Node 兼容性等多个方面。适合希望提升生产力和代码质量的开发者深入了解和应用。
12、CSS Intelligence: Speculating On The Future Of A Smarter Language(英文)
CSS 正在从单纯的样式语言转型为具备逻辑和环境感知能力的“智能”语言。新特性如容器查询、if() 函数等让 CSS 能动态响应组件环境,减少对 JavaScript 的依赖,提升性能和可访问性。但随之而来的是学习门槛提升、调试复杂、工具依赖加重等问题。开发者对 CSS 智能化褒贬不一,作者认为应在增强表达力的同时,坚守声明性和可读性,谨慎推进逻辑特性,避免让 CSS 变得难以维护。
深度总结
CSS 的演变:从表现到智能
CSS 最初被设计为纯粹的表现层语言,专注于字体、颜色、布局等视觉样式,与内容和逻辑严格分离。随着时间推移,CSS 逐步引入了更复杂的功能,例如 Flexbox、Grid 和媒体查询,使其能够根据设备和用户偏好自适应布局。这些特性让 CSS 具备了“上下文感知”能力,即根据环境自动调整样式。
智能化特性与新能力
近期,CSS 的智能化趋势愈发明显。容器查询(container queries)允许组件根据父容器的尺寸或自定义属性(如 CSS 变量)动态调整样式。例如,一个按钮可以根据父级的 --theme 变量自动切换明暗模式,无需依赖 JavaScript。if() 函数的提出,则为 CSS 带来了条件逻辑,类似于编程语言中的三元运算符,未来有望实现更复杂的样式判断。
CSS 与 JavaScript 的边界变化
CSS 的新特性正在模糊与 JavaScript 的界限。过去,交互和条件样式主要依赖 JavaScript。现在,许多原本需要脚本实现的功能,如动画、响应式布局、甚至部分交互(如手风琴、模态框),都可以通过纯 CSS 实现。这一变化降低了对 JavaScript 的依赖,简化了代码结构,提高了性能和可访问性。
社区分歧与挑战
开发者对于 CSS 智能化的态度存在分歧。一部分人认为,原生条件逻辑和上下文感知能力是组件化开发的必然需求,可以减少 JavaScript 负担,提高开发效率。另一部分人则担心,CSS 变得过于复杂,失去原有的简洁和易学性。逻辑分散在 CSS 和 JavaScript 之间,可能导致维护难度上升,调试变得更加棘手。
未来展望与风险
CSS 的未来方向是增强表达力,同时保持声明式和可读性。例如,@when ... @else 等条件规则、功能更强的选择器、原生作用域(@scope)等,都在推动 CSS 向更智能但不失本质的方向发展。然而,功能增强也带来了学习曲线陡峭、工具链依赖加重、调试复杂度提升等问题。如何在增强能力与保持易用性之间取得平衡,是 CSS 未来发展的关键议题。
13、Getting started with Claude 4 API: A developer’s walkthrough(英文)
Claude 4 API以强大的推理能力、丰富的开发特性和高性价比,在代码生成、AI代理和多模态应用等领域领先同类产品,适合企业和高复杂度AI项目开发。
深度总结
Claude 4 API 概述
Claude 4 是 Anthropic 推出的新一代 AI 语言模型,分为 Claude Opus 4 和 Claude Sonnet 4 两个版本。Opus 4 适合需要深度推理和复杂分析的场景,Sonnet 4 更适合日常开发,兼顾性能与效率。两者均基于 Constitutional AI 框架,强调安全、可靠和高可用性。
主要应用场景
- 代码辅助:Claude 4 在多种编程语言下表现出色,能够理解复杂算法,优化代码,甚至根据自然语言描述生成完整函数。
- 内容生成:适用于博客、营销文案、技术文档和虚构内容创作,能够理解品牌、语境和语气,输出高质量文本。
- AI 助手与代理:支持长对话上下文,能处理多步任务,适合集成外部 API,保持一致的人格设定。
- 客户支持:可集成到客服系统,理解用户问题并给出专业回应。
- 数据分析:具备处理数据集、报告和洞察分析的能力。
环境与账户配置
开发前需注册 Anthropic 账户并充值至少 5 美元。API Key 是主要的认证方式,建议为不同环境生成独立 Key,并通过环境变量管理,避免硬编码。API 支持版本控制,通过 anthorpic-version 头指定,便于平滑升级。
价格与计费
Claude 4 采用基于 token 的计费模式,输入和输出 token 分别计费,输出 token 单价略高。Sonnet 4 适合常规任务且成本较低,Opus 4 适合高复杂度任务。优化提示词、缓存重复请求、使用流式响应有助于控制成本。
开发环境与 SDK
官方提供 Python 和 JavaScript/TypeScript SDK,便于集成。Python 适合 AI 应用,JS/TS 适合 Web 和全栈开发。其他语言可直接通过 REST API 调用。推荐在 IDE 中配置环境变量管理 API Key,提升安全性和开发效率。
API 核心用法
认证通过 x-api-key 头实现,SDK 会自动处理。消息 API 采用对话格式,支持多轮交互,消息分为 “user” 和 “assistant” 两种角色。API 支持纯文本和结构化数据,便于灵活扩展。
新增能力
- 代码执行工具:Claude 4 支持 Python 代码执行,能实时计算、生成可视化图表,适合数据分析和科学计算。
- Files API:支持上传和处理多种文件格式(如 PDF、图片、文本),可在对话中引用并分析文件内容。
- MCP 连接器:Model Context Protocol 允许扩展 Claude 功能,安全集成外部数据源和工具,便于企业自定义。
- Prompt 缓存:最长缓存一小时,适合处理大文档和模板场景,提升性能并降低成本。
高级特性与优化
- 流式响应:支持边生成边输出,提升长文本生成和对话体验。
- 视觉与多模态能力:可分析图片、图表、文档等多种视觉内容,适合文档处理和可访问性场景。
- 系统提示与行为定制:通过系统提示自定义模型行为,适应不同品牌和业务需求。
- 批量处理与异步操作:支持大批量请求和异步处理,适合高并发和大数据场景。
性能与模型对比
Claude 4 在 SWE-bench、Terminal-bench 等基准测试中表现突出,尤其在代码生成和复杂推理任务上优于 GPT-4.1、Gemini 2.5 Pro 等主流模型。Opus 4 适合高复杂度任务,Sonnet 4 性能与成本平衡。Gemini 2.5 Pro 在内容生成和数据分析上表现优异,DeepSeek R1 适合开源和预算有限项目。
选型建议
- 企业级开发:Opus 4 适合复杂项目,Sonnet 4 适合生产环境和成本敏感场景。
- 内容与研究:Gemini 2.5 Pro 适合大规模内容生成和数据分析。
- 预算有限:DeepSeek R1 和 GPT-4o 适合开源和多模态需求。
Claude 4 API 在推理、代码、内容生成等方面具备明显优势,配合丰富的 SDK 和新特性,为开发者提供了高效、安全的 AI 应用开发平台。
14、A step into the spatial web:The HTML model element in Apple Vision Pro(英文)

visionOS 26默认支持HTML model元素,网页可直接嵌入3D模型,支持交互、动画和HDR光照。开发者通过简洁API控制模型,兼容USDZ格式,推动Web与空间计算融合,提升3D内容可访问性与标准化。
深度总结
Apple Vision Pro中的HTML model 元素:空间Web的关键进展
Apple Vision Pro的visionOS 26版本默认启用了HTML model 元素,并引入了全新的API。这一变革让Web开发者能够直接在网页中嵌入和控制3D模型,为空间Web体验奠定了基础。
model 元素的核心能力
model 元素允许开发者通过简单的HTML标签嵌入3D资产(如USDZ文件)。在Vision Pro等空间平台上,用户可以以立体3D的方式查看模型,仿佛模型真实存在于网页之中。开发者可以通过属性控制模型的缩放、旋转、位置、光照环境,以及动画播放等。
资源加载与ready Promise
3D模型的加载需要时间。model 元素通过ready Promise暴露加载状态,开发者可通过await确保模型资源完全可用后再进行操作。例如:
交互模式:Orbit与自定义变换
stagemode="orbit"属性让用户可以通过手势旋转模型,实现类似AR Quick Look的交互体验。对于更复杂的需求,开发者可直接操作entityTransform属性,利用DOMMatrix进行平移、旋转和缩放。例如:
teapot.entityTransform = new DOMMatrix().translate(0, 0, -0.5).rotate(0,90,0);
模型尺寸与边界信息
每个模型文件都包含尺寸和中心点信息。加载后,开发者可以通过boundingBoxCenter和boundingBoxExtents获取这些数据,进一步自定义模型在场景中的表现。
光照环境与environmentMap
真实感渲染依赖于环境光照。model元素支持通过environmentmap属性指定环境贴图,推荐使用HDR或EXR格式的equirectangular投影图像。开发者可监听environmentMapReady Promise,确保光照资源加载完毕后再渲染模型。
动画支持
如果模型文件包含动画,model元素可通过play()、pause()、currentTime和playbackRate等API进行控制。HTML属性autoplay和loop可声明式配置动画行为。
USDZ与内容制作
USD(Universal Scene Description)是由Pixar开源的3D内容标准。USDZ是其打包格式,广泛支持于主流3D工具。开发者可通过Reality Composer Pro、iPhone/iPad的Object Capture或Blender等工具创建和导出USDZ模型。
规范进展与反馈
model元素的API正在W3C和WHATWG标准化过程中。WebKit团队鼓励开发者反馈使用体验,以推动空间Web标准的完善。