第3期:AI编程工具生态全景解析
本期深度剖析当前AI编程工具市场的技术格局,系统对比GitHub Copilot、Cursor、Claude Code等12款主流产品的核心优势与适用场景,并结合前端工程化演进、跨平台开发实践等前沿技术动态,为开发者提供基于实际业务需求的AI工具选型决策框架。同时精选9篇深度技术文章和多个高价值开源项目,助力技术团队在AI原生开发时代构建高效的工程化体系。
对于所有的文章,我都会进行深度总结,可以先打开总结,如果看了总结之后,觉得有价值,再去看原文,因为原文可能会有很多细节,而总结会帮你过滤掉很多细节,只保留最重要的信息。
卷首语
最近AI持续在编程领域发力,各个公司开始井喷式的推出自家的编程工具。从微软的GitHub Copilot率先突破,到Cursor的异军突起,再到国内各大厂商的跟进,AI编程工具已经成为开发者必不可少的效率神器。这些工具各有特色,有的专注代码补全,有的强调上下文理解,有的则打造完整的AI原生IDE体验。
主流AI编程工具盘点
GitHub Copilot - 由微软在2021年6月正式发布,基于OpenAI Codex模型。作为第一个大规模商业化的AI编程助手,它的优势在于:深度集成VS Code生态、支持50+编程语言、强大的代码补全能力、庞大的用户基础(超过180万付费用户)。
Cursor - 由Anysphere公司开发,2022年成立,2023年发布。四位MIT本科生创立的这家公司在2024年迅速崛起,其优势包括:AI原生IDE设计、强大的多文件编辑能力、支持自然语言对话编程、项目级代码理解、与VS Code完全兼容。
Augment Code - 由Augment Code公司开发,2024-2025年快速崛起的AI编程平台,基于Claude Sonnet 4模型。优势包括:SWE-bench基准测试65.4%排名第一、支持20万token超长上下文、多文件智能编辑、多模态输入支持(截图、Figma等)、高度自主的Agent模式、与主流IDE深度集成。
Claude Code - 由Anthropic在2025年5月正式发布的专门AI编程工具,基于Claude Opus 4和Sonnet 4模型。优势包括:深度codebase理解能力、与VS Code和JetBrains原生集成、支持无缝结对编程、直接在开发者文件中显示编辑、GitHub Actions支持后台任务。
Replit Agent - 由Replit公司在2023年推出AI功能,2024年升级为Agent模式。其优势是:无需本地环境的云端开发、从想法到部署的一站式体验、支持自然语言生成完整应用、强大的协作功能。
Gemini CLI - 由Google在2025年6月26日发布的开源AI命令行编程工具,基于Gemini 2.5 Pro模型。优势包括:完全免费使用(每分钟60次、每日1000次请求)、开源Apache 2.0协议、终端环境原生支持、支持自然语言对话编程、内置Google搜索功能、MCP协议扩展支持。
通义灵码 - 阿里云在2024年正式发布的AI编程助手。优势包括:深度集成阿里云生态、针对中文开发者优化、支持Java/Python等主流语言、企业级私有化部署、免费提供给个人开发者。
文心快码 - 百度在2024年推出的AI编程工具,现已升级为独立IDE。优势包括:强大的中文语义理解、设计稿一键转代码、支持MCP协议、多模态交互能力、百度生态深度整合。
Trae - 字节跳动在2025年初发布的AI编程工具。优势包括:完全免费使用、中文友好界面、多模型支持(Claude、GPT-4等)、快速响应、Builder模式一键生成项目。
Codeium - 由Exafunction公司开发,2021年创立,2022年转型AI编程。优势包括:完全免费使用、支持70+编程语言、多模型选择、插件形式轻量集成、自然语言搜索功能。
Amazon CodeWhisperer - 亚马逊在2022年推出预览版,2023年正式发布。优势包括:深度集成AWS生态、内置安全扫描功能、企业级合规支持、个人版免费使用、针对AWS服务优化。
Tabnine - 早在2019年就上线的AI编程助手,算是这个领域的先驱。优势包括:支持本地部署保护隐私、轻量级资源占用、多语言支持、企业级安全、可定制化程度高。
可以看出,AI编程工具领域的竞争非常激烈,从用户最真实的体验来看,目前Claude Code 和 Augment 的口碑最好,Cursor 和 GitHub Copilot 使用的人数最多。
本周头条
1、unibest 3.0 发布,unibest 是一个针对 uniapp 的整合包,可以开箱即用。
2、Gemini CLI以开源的形式发布,发布不到10小时就在 Github 上收获了 10k 的 Star,到目前为止已经有 36+k 的 Star。关键点在于免费,每天有1000次免费请求,应该对标的是 Claude Code,由于其免费的特性,还可以用来做文件整理助手。
3、百度文心快码AI IDE上线,首创设计稿一键转代码、支持MCP,它的名字叫Comate AI IDE。

4、京东的Taro团队正式发布了 HarmonyOS C-API 版本,让开发者可以使用 React 开发鸿蒙应用。
5、Vite 7.0 正式发布,以更高性能、更强兼容性和更开放的生态迈入新阶段,Rolldown打包器、DevTools工具和环境API等创新推动前端开发体验升级,社区协作和生态融合成为其持续进化的关键动力。

6、Gemini Robotics On-Device 是一款可本地运行、具备通用灵巧操作和极强任务适应性的机器人 AI 模型,支持低延迟、离线应用,并能通过少量演示快速迁移到新任务和不同机器人平台,推动机器人智能的普及与创新。
7、码上飞于2025年6月20日在华为开发者大会(HDC2025)上作为首批鸿蒙Agent生态成员正式亮相,并成为全球首个支持生成华为鸿蒙应用的AI Agent平台。

8、Kimi-Researcher是月之暗面公司面向深度研究任务推出的AI Agent,具备主动澄清、推理、检索和高质量信息筛选能力,能自动生成详实报告和可视化网页。
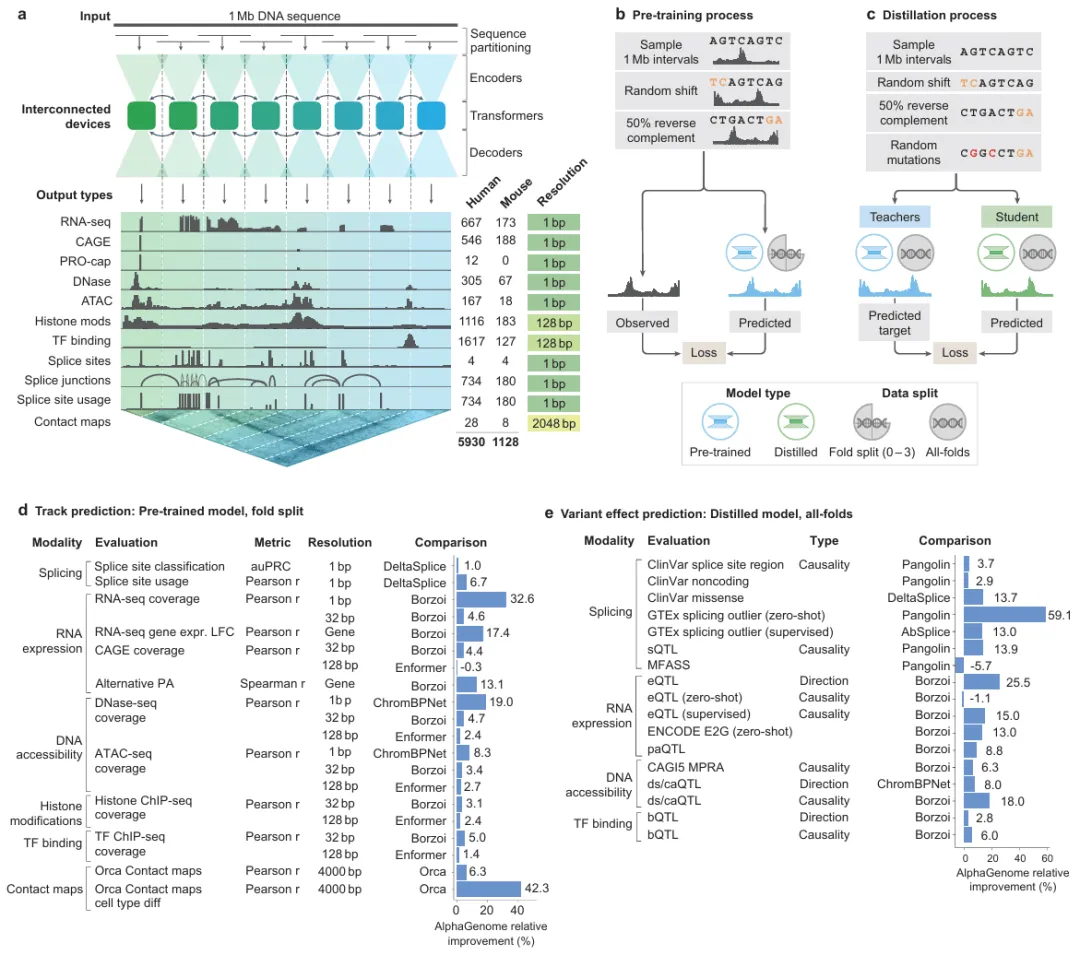
9、AlphaGenome是DeepMind推出的DNA序列AI模型,能以百万碱基对为单位,预测多种分子特性,实现全基因组变异效应的高精度注释,显著提升疾病机制解析和基因组研究能力,已开放非商业使用。
10、6月26日,小米 YU7 正式公布了它的价格,并且一小时大定28.9万台。

11、Google 全面开源 Gemma 3n,Gemma 3n是Google发布的本地多模态开源大模型,具备高效显存利用、灵活架构和卓越性能,支持文本、图像、音频、视频等多种输入,广泛适配主流AI库。
深度阅读
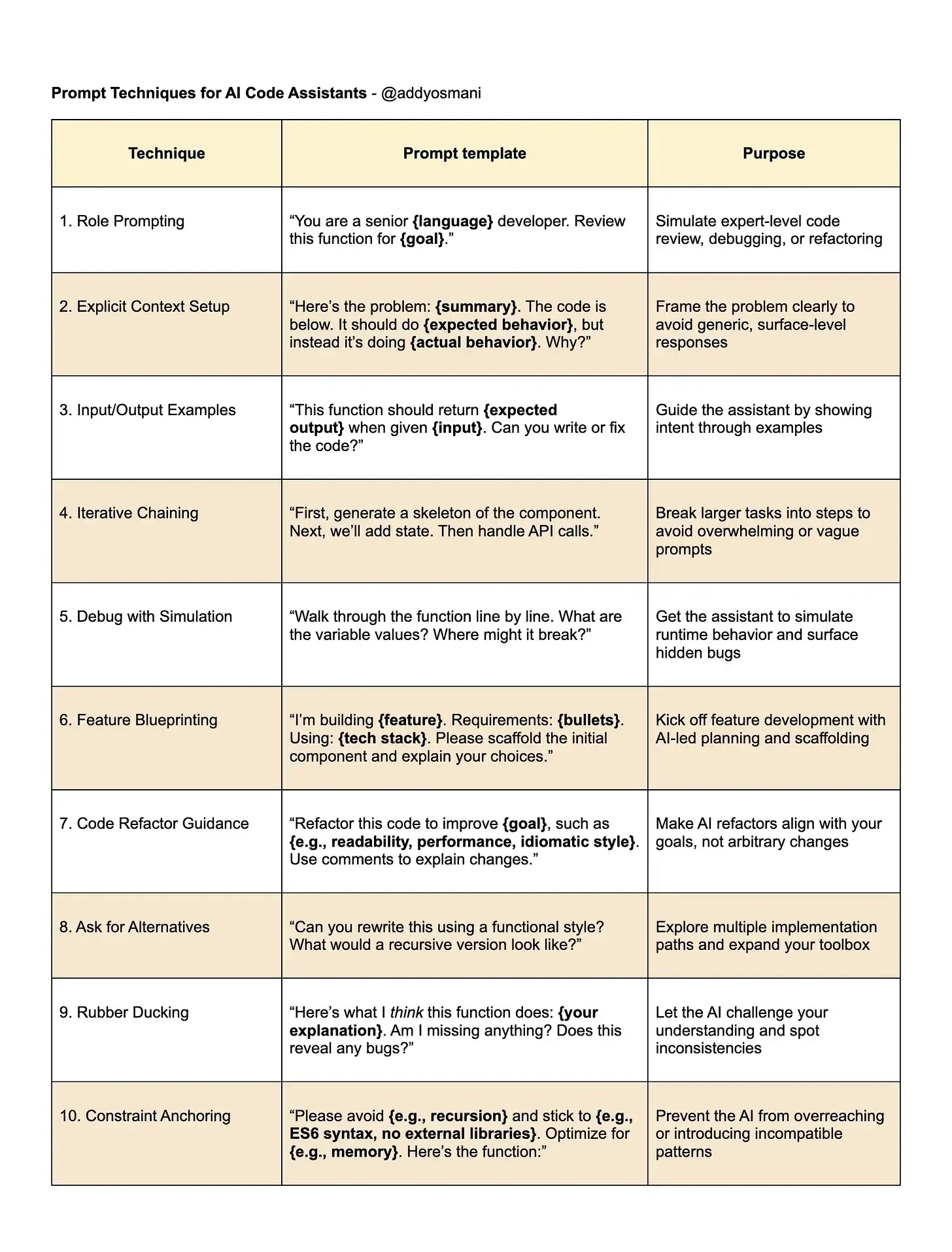
这篇文章有英文原版,作者很系统很详细很全面的介绍了一个好的提示词应该包含哪些内容,如果你是才接触提示词的新手,阅读这篇文章能够让你快速的并且系统的学习应该如何编写一个好的提示词。
一个好的提示词,应该是全面,不具有歧义,比如:帮我创建一个个人博客网站。这就是一个错误的提示词,会让AI造成巨大的歧义。
正确的提示词应该是:你是一个经验丰富的前端工程师并且还是一个经验丰富的UI设计师,现在我需要一个个人博客网站,请帮我设计一个简洁大方的UI,并且我的博客包含文章列表、文章详情、留言板、关于我等页面,首页要包含一个文章列表,文章列表要包含标题、摘要、作者、发布时间、阅读量、点赞数、评论数、阅读时长等信息。首页头部要包含一个搜索框,搜索框要包含一个输入框和搜索按钮,搜索按钮要包含一个搜索图标…
深度总结
AI 编程助手已成为开发者日常工作的重要工具。它们能够自动补全代码、修复错误,甚至生成完整模块。然而,AI 输出的质量高度依赖于提示(prompt)的设计。提示工程(Prompt Engineering)因此成为开发者必备的技能。一个模糊的请求只会得到泛泛的答案,而精心设计的提示能带来准确且富有创意的解决方案。
高效提示的核心原则
-
提供丰富上下文
AI 对你的项目一无所知,除非你主动提供信息。包括编程语言、框架、库、具体代码片段和错误信息。举例:描述 Node.js 函数、使用的技术栈、预期与实际行为。 -
明确目标与问题
问题描述要具体。例如,不要只说“代码不工作”,而要指出“函数返回 undefined 而不是预期结果”,并附上相关代码和输入输出示例。 -
分解复杂任务
将大任务拆分为小步骤。比如,先生成组件骨架,再添加状态管理,最后处理 API 调用。每一步都明确指令,避免 AI 混淆。 -
输入/输出示例
用具体例子说明预期行为。例如,给定数组 [3,1,4],函数应返回 [1,3,4]。这种 few-shot prompting 能有效减少歧义。 -
角色设定
让 AI 扮演特定角色,如“资深 React 开发者”或“性能专家”,能获得更结构化、专业的建议。 -
迭代优化
与 AI 的对话是互动过程。初次回答不理想时,补充细节或调整要求,逐步引导 AI 达到预期目标。 -
代码清晰一致
保持代码风格、命名和注释一致,有助于 AI 理解上下文并延续你的习惯。
调试与重构的提示模式
-
调试
明确描述问题、症状和预期行为。附上错误信息和最小可复现示例。可以让 AI 逐行分析变量值,模拟人类调试过程。也可让 AI 扮演代码审查员,指出潜在错误和不良实践。 -
重构
明确重构目标(如可读性、性能、风格)。提供完整代码和相关上下文。鼓励 AI 在输出代码的同时解释更改理由。角色扮演能提升建议质量。
新功能实现的提示策略
-
高层到细节
先用自然语言描述需求,再分解为具体任务。每一步单独提示,便于逐步实现和测试。 -
上下文与参考
提供现有项目的相关代码或风格约定,让 AI 生成更一致的实现。 -
注释与 TODO
在代码中用注释描述需求,AI 可据此自动补全。 -
输入输出示例
明确函数的输入输出,有助于 AI 理解需求。 -
迭代完善
结果不理想时,补充约束或细节,反复优化。
常见反模式与规避方法
-
模糊提示
缺乏上下文和细节,导致无用答案。应补充具体信息。 -
超载提示
一次要求太多,AI 难以处理。应拆分为多个小任务。 -
缺失问题
只给代码不提需求,AI 无法判断目标。应明确提出问题。 -
模糊成功标准
优化目标不清,AI 难以把握方向。应量化或限定改进目标。 -
风格不一致
提示风格混乱,AI 易混淆。应保持表达方式一致。 -
引用不清
“上面代码”易混淆,应直接引用具体代码。
结语
提示工程是开发者与 AI 高效协作的关键。通过提供详尽上下文、明确目标、分步引导和持续优化,AI 能成为可靠的开发伙伴。严谨的提示设计不仅提升代码质量,也能帮助开发者自身成长。
2、为什么跨平台框架可以适配鸿蒙,它们的技术原理是什么?(中文)
鸿蒙能被多种跨平台框架适配,关键在于其对 Linux 兼容、标准编译工具链和系统接口的支持。Flutter 适配成本低,React Native 依赖 C API 映射,uni-app x 侧重前端“翻译”,KMP/CMP 需深度定制,适配难度最大。
深度总结
跨平台框架适配鸿蒙的技术原理
鸿蒙(HarmonyOS)逐步成为主流平台,跨平台框架的适配成为开发者关注的重点。当前主流支持鸿蒙的跨平台框架包括 Flutter、React Native、uni-app x 以及 KMP/CMP。它们的适配方式各有侧重,但都依赖于鸿蒙提供的底层兼容能力,如 musl libc、标准 POSIX API、Clang/LLVM 以及 GN/Ninja 构建体系。
Flutter 的适配机制
Flutter 适配鸿蒙的核心在于其嵌入层设计。Flutter Engine 的构建依赖 GN 和 Ninja,这与鸿蒙的编译子系统天然契合。适配过程中,开发者需扩展 ohos 嵌入层,调整窗口管理、输入事件、生命周期管理等系统服务的对接方式。引擎层则需适配图形、文本渲染和平台通道通信机制。Flutter Engine 最终被编译为 libflutter.so,打包进 flutter.har,通过鸿蒙定制的 Clang/LLVM 生成可在鸿蒙运行的二进制文件。
第三方依赖的适配通过 gclient sync 和 git patch 实现。例如,针对 skia 增加 FontConfig_ohos 和 SkFontMgr_ohos,以支持鸿蒙的字体管理。Dart 代码的编译流程独立于 LLVM,采用 Dart 前端编译器生成 kernel IR,再通过适配的 gen_snapshot 工具 AOT 编译为目标架构的机器码。
在渲染层,Flutter 通过 XComponent 获取底层 OHNativeWindow,并利用 VK_OHOS_surface 实现 Vulkan 渲染。原生组件通过 ArkUI C API 嵌入到 Flutter 的 PlatformView 中。平台交互通过 MethodChannel 实现,Dart 到 C++ 再到 ArkTS 的调用链条保证了功能的完整性。
React Native 的适配方式
React Native for OpenHarmony 主要依赖 JS 层的灵活性。其适配核心在于将 React 控件映射为 ArkUI 组件。新架构下,JSI 允许 JS 代码直接操作 C++ 对象,鸿蒙通过 RNOHAppNapiBridge.cpp 实现 JSI 到 NAPI 的桥接。适配过程中,采用补丁方式避免直接修改第三方库,保证多平台兼容。
ArkUI 的 C API 支持原生 C++ 代码与 ArkUI 框架深度交互,包括组件创建、属性设置、事件监听等。Taro 等框架通过 C API 下沉大部分逻辑至 C++ 层,提升性能。TurboModule 分为 ArkTSTurboModule 和 cxxTurboModule,分别处理依赖系统能力和纯数据计算的场景。
uni-app x 的适配逻辑
uni-app x 采用 uts 作为中间层,将 Vue 语法编译为 ArkTS。uvue 作为“翻译工具”,负责将 uts 版 Vue 框架的组件、数据绑定和 UI 编排转化为 ArkUI 组件。适配主要集中在前端部分,后端编译直接对接 ArkUI,支持与 ArkTS 混编。
KMP/CMP 的适配挑战
KMP(Kotlin Multiplatform)和 CMP(Compose Multiplatform)适配鸿蒙的难度较高。KMP 主要有 Kotlin/JS 和 Kotlin/Native 两种方式。Kotlin/JS 通过将 Kotlin 编译为 JS,利用 ArkTS API 实现平台对接,但性能和产物体积有限。Kotlin/Native 则通过鸿蒙的 LLVM 直接编译为可执行文件,性能更优,但对编译器和 LLVM 版本的依赖更重。
适配过程中需新增 Harmony Target、定制交叉编译 toolchain、适配 NAPI 以实现系统 API 调用。KuiklyBase 提供了 KMP 适配鸿蒙的基础能力,KuiklyUI 和 ovCompose 分别采用原生 OEM 渲染和 Skia 自绘方案。ovCompose 通过 Skiko 适配鸿蒙,利用 XComponent 作为画布,实现与原生组件的混排。
结语
跨平台框架适配鸿蒙的核心在于底层兼容能力和对系统 API 的深度对接。Flutter、React Native、uni-app x 适配成本相对较低,KMP/CMP 适配则需投入更多工程资源。开发者可根据项目需求和团队能力选择合适的适配方案。
3、分享一个讲透任意知识点的万能框架,程序员提升个人技术影响力必备!(中文)
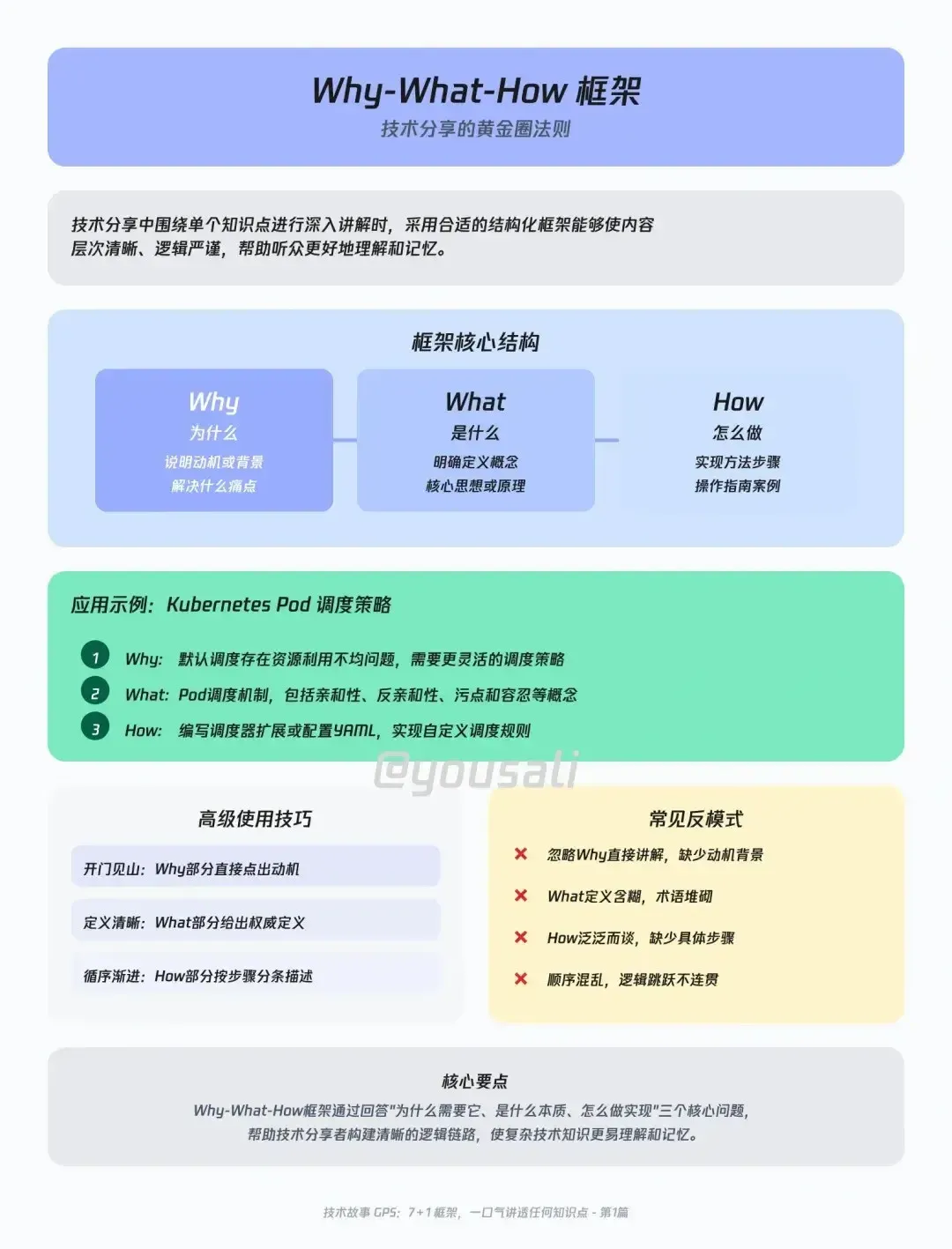
本文系统梳理了7+1种技术分享框架,强调结构化、故事化和分层递进的表达方式,配合AI工具和行动清单,帮助程序员高效传递复杂知识,提升个人技术影响力,避免常见表达误区,实现内容的高效吸收与落地。
深度总结
技术分享的万能框架概述
本文系统梳理了适用于技术分享的多种结构化表达框架,旨在帮助技术人员提升知识传递的清晰度和影响力。内容涵盖了从问题引入、层层递进、全方位剖析,到故事化表达和时间线梳理等多种方法,适合不同场景下的技术讲解。
Why‑What‑How:问题驱动的三段式结构
此框架强调先提出痛点(Why),再解释概念(What),最后给出具体操作(How)。例如,介绍 Pod 调度时,先描述资源分配不均的实际问题,再用类比解释 PodAntiAffinity 的作用,最后通过配置示例展示实际操作。该方法有助于听众快速理解动机、原理和实践步骤。
层层递进:由浅入深的知识剖析
适用于复杂技术的讲解。分为表层(简要概括)、深层(核心机制)、更深层(性能与设计权衡)、专家视角(前沿进展)。以 Transformer 为例,先说明其并行计算优势,再剖析多头自注意力机制,进一步讨论性能瓶颈及优化,最后介绍 MoE 和稀疏注意力等前沿方向。
F‑R‑S‑C‑O:五维度全景分析
从功能(F)、合理性(R)、稳定性(S)、兼容性(C)、运维(O)五个角度全面评估技术方案。例如,分析 Raft 协议时,分别阐述其一致性保障、设计易懂性、高可用性、主流兼容性和成熟的运维经验。
英雄之旅(Failure-Driven Story):故事化复盘
通过事故(Fault)、发现(Detect)、缓解(Mitigate)、预防(Prevent)、教训(Learn)五步,讲述技术成长过程。以支付接口故障为例,详细描述问题暴发、定位、应急处理、后续修复和团队收获,增强内容的感染力和实用性。
SCQA:悬念式问题引入
采用 Situation(背景)、Complication(冲突)、Question(提问)、Answer(回答)四步,快速制造认知缺口,吸引听众注意力。例如,数据库性能瓶颈的案例,通过现状、冲突、核心问题和解决方案的递进,清晰展现问题与答案。
PREP:观点论证的结构化表达
适合会议发言和决策建议。结构为 Point(观点)、Reason(理由)、Example(案例)、Point(重申)。如建议引入 AI Code Review,先亮明观点,解释原因,举例说明效果,最后再次强调结论。
时间轴:技术演进的纵向梳理
通过“过去—现在—未来”三阶段,展现技术的发展脉络。例如,游戏渲染技术从固定管线到实时光线追踪,再到 AI 驱动的未来趋势,帮助听众理解技术演进的逻辑。
选型矩阵:框架对比与应用场景
文中附有一页表格,比较各框架的核心思路、适用问题和典型场景。便于根据内容和听众需求选择合适的表达方式。
常见误区与改进建议
总结了五个易犯错误,包括顺序错乱、文字墙、缺乏例子、故事无结尾、表格信息过载。建议在讲解时注意结构清晰、内容精炼、案例具体。
AI助力内容生成
提供了高效的 Prompt 模板,指导如何利用 AI 快速生成结构化技术讲稿。强调明确受众、知识点和框架要求,结合代码示例、性能数据和常见误区,提升内容质量和实用性。
行动建议
建议读者立即实践:用 Why‑What‑How 写提纲,复盘一次故障经历,优化 PPT 内容结构。强调短句、列表和代码框的使用,有助于提升表达的清晰度和可读性。
4、一天 AI 搓出痛风伴侣 H5 程序,前后端+部署通吃,还接入了大模型接口(万字总结)(中文)
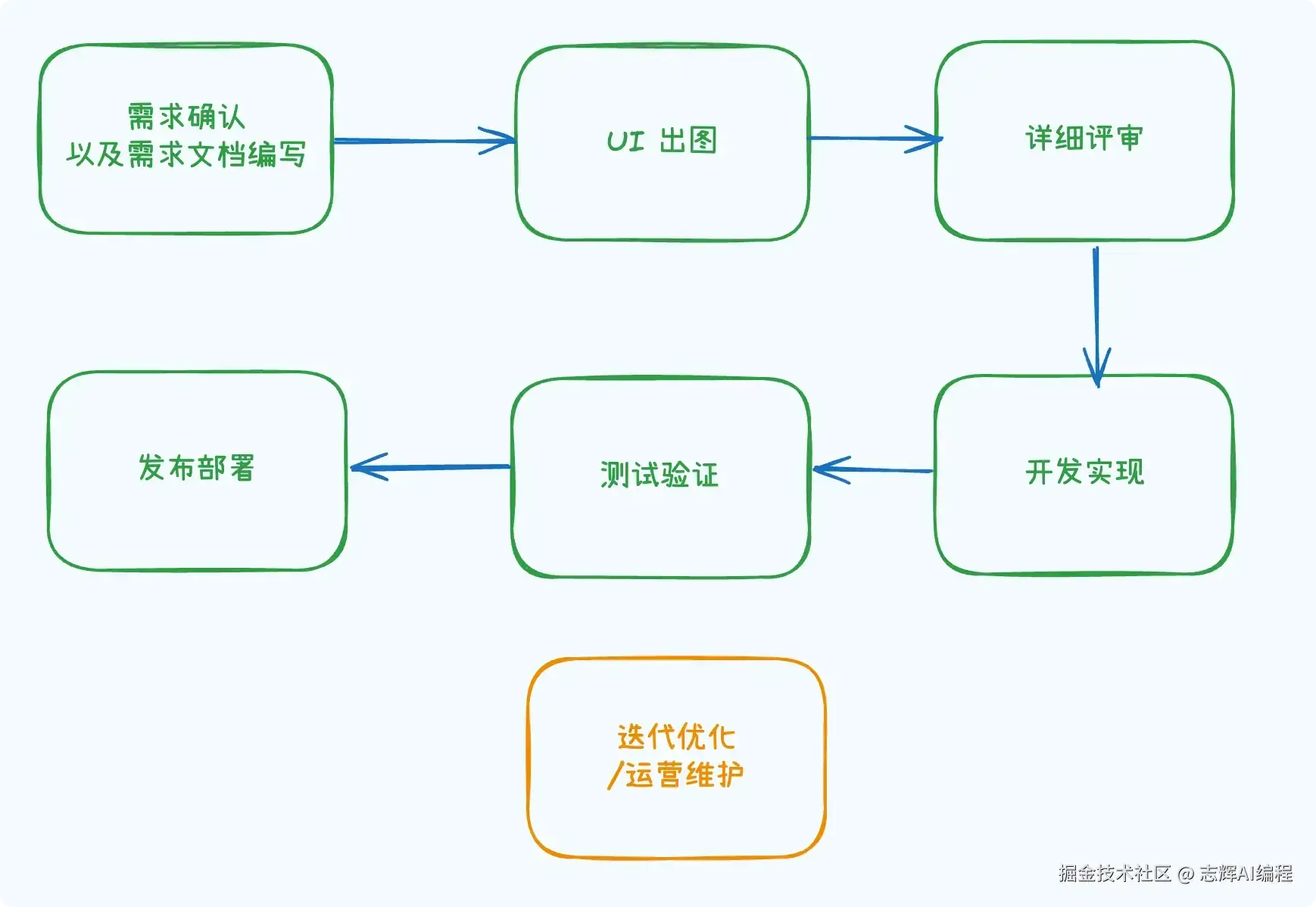
作者以自身为例,展示了如何借助AI工具独立高效开发“痛风伴侣”H5应用,从需求、数据、前后端开发到部署全流程仅用10小时、300元完成,强调AI极大降低了开发门槛,让个人创意快速落地成为可能。
深度总结
项目背景与目标
作者是一名大数据架构师,同时也是痛风患者。基于自身需求,他开发了一款面向痛风患者的 H5 应用。该应用通过拍照识别食物嘌呤含量,辅助用户进行饮食管理。项目采用前后端一体化开发,集成大模型接口,实现从需求分析到部署上线的完整流程。
产品开发流程
开发流程分为六个阶段:需求分析、数据准备、开发与联调、部署上线、运营维护、成本核算。前四个阶段构成产品的核心开发环节,后续则关注产品的持续优化与推广。
成本与资源评估
传统开发通常涉及多角色协作,周期至少半个月至一个月。个人开发需兼顾多项职责,时间与精力投入显著。AI 编程工具的引入提升了开发效率,降低了实现门槛。
需求分析
产品包含三个核心模块:识别、食物、我的。识别模块支持拍照或上传图片,利用大模型识别食物并给出嘌呤含量及建议。食物模块展示常见食物的嘌呤含量,支持筛选与图片展示。我的模块记录用户尿酸历史,提供数据可视化与历史查询。需求文档通过大模型工具生成,需人工审核确保准确性。
数据准备
数据权威性至关重要。作者选用卫健委发布的官方数据,确保食物嘌呤含量的准确性。数据以 PDF 格式获取,需转换为 markdown,再由大模型辅助生成 JSON 数据结构。图片资源需人工筛选与命名,确保与数据一一对应。
前端开发
前端开发采用 bolt 工具进行初步界面生成,通过提示词快速获得美观且交互完善的 UI。后续细节调整与 bug 修复在 Cursor 中完成。界面样式可通过截图、元素选择等方式精细调整。代码通过 GitHub 管理,图片与数据文件需放置于 public 目录,确保前端可正常访问。移动端适配通过浏览器调试工具实现。
后端开发
后端采用 fastify 框架,负责调用阿里云通义千问大模型 API,实现图片识别与数据返回。API_KEY 等敏感信息通过 .env 文件管理,避免泄露。接口文档详细记录请求与响应字段,确保前后端对接顺畅。前端根据文档调整请求逻辑,实现数据的准确传递与展示。
部署与上线
采用 railway 平台进行前后端一体化部署,简化配置流程。环境变量管理、自动化部署、临时域名分配等功能降低了上线门槛。配置文件由 AI 辅助生成,进一步提升效率。代码推送至 GitHub,railway 平台自动拉取并部署。部署过程中遇到的问题可通过日志反馈,结合 AI 工具快速定位与修复。
运营维护与优化
图片上传需考虑数据体积,建议压缩后再上传。后端需提升请求体大小上限,防止接口超时。API_KEY 等敏感信息需妥善保护,定期进行代码安全审查。产品上线后需持续优化功能,提升用户体验。推广渠道包括社群、朋友圈等,积极收集用户反馈,迭代产品功能。
成本核算
项目整体开发周期约为一天,主要成本为个人时间与工具订阅费用(bolt、Cursor、域名等),总计约 300 元人民币。与传统团队开发相比,成本大幅降低,效率显著提升。
结语
本项目展示了 AI 编程工具在个人开发中的高效应用。通过合理分工与工具协作,个人开发者也能在短时间内完成高质量的前后端一体化产品。关键在于需求梳理、数据权威性、接口文档准确性以及持续的优化与维护。
5、JavaScript 毁了 Web,并称之为进步(英文)

本文批判了现代网站开发中过度依赖 JavaScript 和复杂框架的现象,指出开发者为追求“开发者体验”而牺牲了用户体验和网站性能,导致网站臃肿、难维护、更新缓慢。作者认为,大多数网站其实只需简洁的服务器渲染和适度的 JavaScript,过度工程化只会增加成本、降低效率。呼吁行业回归以用户为中心、追求高效和可维护性的开发理念,拒绝不必要的复杂性,让网站真正服务于用户和业务目标。
深度总结
JavaScript与现代Web开发的复杂性
现代网站普遍存在性能低下、维护困难等问题。根本原因在于,开发者为追求“应用体验”,引入了大量JavaScript框架和复杂的开发流程。这种趋势始于2010年前后,随着iPhone和Angular等技术的兴起,开发团队试图让网站具备原生App的流畅感。然而,结果并非用户体验的提升,而是复杂度的激增。
从内容为本到开发者为本
Web开发逐渐从关注内容和用户体验,转向以开发者体验(DX)为核心。框架、工具链和抽象层的堆叠,使得开发流程变得高效,但也让网站变得难以理解和维护。例如,简单的页面更新需要经过多层审批和构建流程,内容编辑者和市场人员被排除在外,所有变更都依赖开发团队。
复杂性成为常态
如今,构建网站往往默认需要构建流程、路由层、API层、设计系统等。即使是简单的博客或电商页面,也采用与大型应用相同的技术栈。这导致即便是开发者本人,也难以完全掌控项目全貌。许多本应由Web原生特性(如HTML、缓存、路由)直接支持的功能,被重复造轮子,反而效率更低。
技术栈的自我循环
JavaScript生态不断引入新工具和新模式,试图修复前一轮复杂化带来的问题。例如,Server-side rendering(SSR)、路由管理、元数据处理等功能被重新实现,最终回归到传统CMS的模式,但维护成本和技术门槛却大幅提升。
复杂性带来的连锁反应
技术栈的频繁变动和高复杂度,直接影响到内容发布、营销、SEO等环节。非技术人员难以独立完成内容更新,SEO优化和A/B测试受限于技术实现,用户则面临加载缓慢、交互异常等问题。开发团队成为唯一的“入口”,进一步加剧了对技术的依赖。
JavaScript的合理使用边界
JavaScript本身并非问题。它适合用于需要高度交互和实时性的场景。但大多数网站只需展示内容、实现基本交互,无需复杂的前端框架。许多功能可以通过精简的原生JavaScript或现代CSS实现,避免不必要的性能损耗和维护负担。
权力结构的变化
随着技术栈的复杂化,开发团队掌握了网站的绝对控制权。内容、营销、SEO等环节都需依赖开发者,组织效率下降,成本上升。这种结构性问题源于对“现代化”开发方式的盲目追求,而非实际业务需求。
回归本质的建议
网站建设应以用户体验、性能和可维护性为核心。采用服务器渲染HTML、语义化标记、简洁模板和合理的JavaScript使用,能够满足绝大多数需求。选择工具时应以实际效果为导向,避免为技术而技术。
结语
Web的复杂化是人为选择的结果。开发者和相关从业者应主动质疑现有架构,推动以结果为导向的技术决策。只有回归Web的本质,才能实现高效、可持续的开发与运营。
Kubernetes 网络以每 Pod 独立 IP、无 NAT 直连和本地路由为基础,结合 CNI 插件、kube-proxy 负载均衡、CoreDNS 服务发现及网络策略隔离,实现了高效、可扩展且安全的容器集群通信,是微服务架构顺畅运行的关键。
深度总结
Kubernetes Networking 概述
Kubernetes 网络是容器化工作负载在生产环境中运行的核心组成部分。它确保集群内各个组件(如容器、服务)能够高效通信,同时也让外部流量能够准确到达目标容器。Kubernetes 通过为每个 Pod 分配唯一 IP,实现了无需 NAT 的直接通信,简化了网络结构,提升了可观测性和调试效率。
NAT 与 Pod 通信
传统 NAT(Network Address Translation)会修改数据包的源或目标 IP,导致外部主机无法直接识别内部通信源。Kubernetes 设计中,每个 Pod 拥有真实的、可路由的 IP,集群内部通信无需 NAT,数据包的源和目标地址始终保持透明。这种设计降低了延迟,便于追踪和排查问题。
微服务架构下的网络模型
在微服务场景下,每个服务运行在独立的 Pod 中,拥有独立 IP。例如,商品、购物车、用户认证、支付等服务可以直接通过 IP 互相访问,无需中间代理或地址转换。这种模式支持高效的服务发现和负载均衡。
Kubernetes 网络三大原则
- Pod 唯一 IP:每个 Pod 拥有独立 IP,避免端口冲突,简化服务发现。
- 无 NAT 通信:Pod 之间直接通信,数据包不经过地址转换,便于调试和策略制定。
- 节点直连路由:节点本地处理流量转发,无需中心化网关,提升性能和可扩展性。
网络挑战与应对
- 动态 IP 管理:Pod 生命周期短暂,IP 频繁变化。Kubernetes 通过 CoreDNS 动态追踪 Pod IP,结合就绪探针确保服务可用性。
- 安全通信:默认情况下,集群内所有 Pod 可互通,存在“东西向”安全风险。可通过 Network Policy 实现分段隔离,或引入 mTLS 加密通信。
- 大规模性能瓶颈:传统 iptables 在大集群下规则数量激增,影响性能。现代 CNI(如 Cilium、Calico)通过 eBPF、BGP 等技术优化转发效率。
核心组件解析
- CNI(Container Network Interface):Kubernetes 网络插件标准,负责为 Pod 分配 IP、创建虚拟网卡、配置路由。常见实现有 Flannel(简单覆盖网络)、Calico(BGP 路由)、Cilium(eBPF 数据面)。
- kube-proxy:运行在每个节点上,将 Service 抽象转化为具体的路由规则。支持 iptables 和 IPVS 两种模式,后者在大规模集群下表现更优。
- CoreDNS:集群内 DNS 服务,负责将服务名解析为 ClusterIP,实现服务发现。
通信路径与服务类型
- Pod-to-Pod:Pod 之间通过 IP 直接通信,无需 NAT。
- Pod-to-Service:Pod 通过服务名访问 Service,由 kube-proxy 负载均衡到后端 Pod。
- External-to-Service:外部流量通过 NodePort、LoadBalancer 或 Ingress 进入集群,最终路由到目标 Service。
服务类型包括 ClusterIP(仅集群内访问)、NodePort(节点端口暴露)、LoadBalancer(云厂商负载均衡)、ExternalName(外部 DNS 别名)。
Ingress 与多应用路由
Ingress 控制器实现 HTTP(S) 路由和 TLS 终止。可通过单一域名下不同路径,将流量分发到多个后端服务,适用于多应用统一入口场景。
网络策略与安全隔离
Network Policy 通过标签和命名空间选择器,精细控制 Pod 之间的流量。可实现环境隔离、互联网访问控制、零信任网络等安全需求。例如,支付服务可通过策略仅允许特定服务访问,并限制外部流量。
常见故障与排查工具
- Pod 不可达:常见原因包括策略过于严格、标签选择器配置错误。可通过 kubectl exec、tcpdump、Netshoot 等工具排查流量路径和策略匹配情况。
- 服务无端点:通常是 Service selector 与 Pod 标签不匹配,需检查并修正标签配置。
结语
Kubernetes 网络体系以唯一 IP、无 NAT、节点直连为基础,结合 CNI、kube-proxy、CoreDNS 等组件,构建了高效、可扩展、易于调试的容器网络环境。通过合理配置服务类型、Ingress、Network Policy,可满足多样化的业务需求和安全要求。
7、怎么在 PWA 中实现 Service Worker 和 WorkBox(英文)
本文系统阐述了如何用Workbox为Web应用集成Service Worker,赋予其离线能力、智能缓存和原生安装体验。Workbox通过模块化和策略化极大简化了PWA开发流程,让Web应用在性能、可靠性和用户体验上全面接近原生App。
深度总结
Progressive Web App(PWA)基础
PWA是一种结合了Web和原生App优点的应用形态。它基于HTML、CSS和JavaScript开发,能够实现如原生App般的体验。例如,用户可以将PWA添加到主屏幕,离线时依然可用,并支持推送通知。PWA的核心特性包括响应式设计、可靠性(即使在网络不佳时也能加载)、可安装性和用户交互性。
PWA的核心组成
-
Web Application Manifest
这是一个JSON文件,描述了应用的名称、图标、主题色、启动页等信息。Manifest让浏览器知道如何在设备上展示和启动PWA。例如,manifest中定义的icon会作为主屏幕图标显示。 -
Service Worker
Service Worker是运行在浏览器后台的JavaScript脚本。它可以拦截网络请求、缓存资源、实现离线访问、处理推送通知等。Service Worker的工作机制类似于“网络代理”,在用户与服务器之间进行调度。例如,用户断网时,Service Worker可以直接从本地缓存中读取数据,保证应用可用。 -
HTTPS
PWA必须部署在HTTPS环境下。只有在安全的连接下,浏览器才允许注册Service Worker,保障数据传输安全。
Service Worker的作用与实现难点
Service Worker的主要职责包括:
- 安装阶段缓存关键资源
- 激活阶段清理旧缓存
- 拦截fetch事件,实现缓存优先或网络优先等策略
手动编写Service Worker代码容易出错,维护成本高。例如,开发者需要自己管理缓存更新、处理各种网络异常。
Workbox简介与优势
Workbox是Google推出的Service Worker开发库。它封装了常用的缓存策略和路由机制,极大简化了PWA开发流程。Workbox支持多种缓存策略,如CacheFirst、NetworkFirst、StaleWhileRevalidate等。开发者只需调用API,无需关注底层细节。例如,使用workbox.routing和workbox.strategies模块,可以几行代码实现复杂的缓存逻辑。
Workbox的主要模块包括:
- workbox-routing:管理请求路由
- workbox-strategies:定义缓存策略
- workbox-precaching:实现静态资源预缓存
- workbox-expiration:自动清理过期缓存
- workbox-window:简化前端与Service Worker的通信
项目结构与关键文件
项目结构清晰,主要包括index.html、style.css、app.js、service-worker.js、manifest.json、offline.html等。
- index.html:主页面,包含天气查询、地理定位、安装按钮等功能
- offline.html:离线提示页面
- style.css:响应式样式,适配多终端
- app.js:核心业务逻辑,包括天气数据获取、地理定位、UI渲染等
- config.js:存储API密钥,便于管理和安全
- manifest.json:定义PWA元数据
- service-worker.js:注册Workbox,配置缓存策略和离线支持
Service Worker与Workbox的集成流程
-
引入Workbox
通过CDN在service-worker.js中引入workbox-sw.js。 -
立即激活新Service Worker
使用workbox.core.skipWaiting()和workbox.core.clientsClaim(),确保新版本立即生效。 -
预缓存核心资源
通过workbox.precaching.precacheAndRoute(),缓存index.html、style.css、app.js等关键文件。 -
API请求缓存
对天气API采用NetworkFirst策略,优先请求网络,失败时回退到缓存。 -
图片缓存
图片采用StaleWhileRevalidate策略,先返回缓存,再异步更新。 -
静态资源缓存
静态资源(如本地JS、CSS、图片)采用CacheFirst策略,提升加载速度。 -
HTML页面离线支持
页面请求采用NetworkFirst策略,网络不可用时回退到offline.html。 -
清理旧缓存
在activate事件中,自动删除不再使用的缓存,保持缓存空间整洁。
App安装与自定义安装提示
通过install.js注册Service Worker,并监听beforeinstallprompt事件,实现自定义安装按钮。用户点击后,触发浏览器的安装提示。安装完成后,通过appinstalled事件确认。
总结
本教程以天气应用为例,系统梳理了PWA的核心原理、Service Worker的作用及Workbox的高效实践路径。通过合理的项目结构和模块划分,开发者可以快速构建具备离线能力、可安装、体验接近原生App的Web应用。

AI让开发更快,但真正的价值在于开发者的专业判断和系统思维。只有掌握基础、善用AI、持续追问“为什么”,才能在AI时代写出高质量、可扩展且安全的代码,成为不可替代的优秀开发者。
深度总结
AI时代下开发者专业能力的重要性
AI工具如GitHub Copilot极大提升了开发效率,尤其对初级开发者帮助显著。然而,开发者的核心价值并非仅在于更快地写出代码,而在于理解代码为何有效、如何融入系统,以及在出现问题时能迅速定位和解决。经验丰富的开发者能够从系统层面思考,确保软件具备可扩展性、健壮性和安全性。AI可以加速开发,但无法替代人类的判断力和系统性思维。
AI与开发者经验的协同效应
AI带来的生产力提升需要开发者的专业判断进行加持。比如,AI能让提交代码的速度提升55%,但只有开发者通过细致的Code Review、完善的测试和对边界情况的把控,才能保证质量不被牺牲。AI减轻了认知负担,开发者则有更多精力投入到架构设计、团队指导和复杂问题的解决中。对于初级开发者,AI降低了上手门槛,但资深工程师的标准制定和经验传授依然不可或缺。
基础能力的不可替代性
AI无法替代开发者对基础能力的掌握。Pull Request、Code Review和Documentation是开发流程的三大基石。Pull Request不仅要说明“做了什么”,更要阐明“为什么要做”,并为团队成员和AI工具提供足够的上下文。Code Review是团队知识传递和质量保障的关键环节。开发者需要关注测试覆盖、数据流、隐藏状态和性能等方面。Documentation则是团队协作和项目可持续发展的保障。结构清晰、内容准确的文档不仅方便团队成员,也为AI工具提供了更好的上下文。
工作流中的关键实践
- Pull Request应保持精简,建议不超过300行,标题需动宾结构,描述要回答“为什么现在做”,并明确标注Breaking Change和反馈需求。
- Code Review时,优先阅读测试,关注数据流和隐藏状态,提出具体改进建议,并肯定优秀设计。
- Documentation建议采用Diátaxis框架,分为教程、操作指南、原理解释和参考文档,便于信息检索和维护。
能力成长路径
| 能力 | 初级 | 中级 | 高级 |
|---|---|---|---|
| Pull Request | 说明“做了什么” | 解释“为什么”,关联Issue | 预判性能/安全影响,主动引导Review重点 |
| Code Review | 简单点赞或否定 | 提出可执行的改进建议 | 指导架构决策,传授经验 |
| Documentation | 更新README | 编写任务导向的操作指南 | 以产品思维维护文档,关注可用性和指标 |
结语
AI正在改变开发方式,但开发者的好奇心、判断力和系统性思维依然是不可替代的。持续追问“为什么”,不断夯实基础,是在AI时代保持竞争力的关键。
9、在这个月,Google Cloud 宣布了哪些 AI 产品(英文)

谷歌云以Gemini CLI、Veo 3等创新产品推动AI普及,强化多模态与安全体系,推出多项开源协议和企业级服务,持续提升AI实用性与安全性,助力开发者和企业高效创新。
深度总结
Gemini CLI与开发者工具
Google Cloud推出了Gemini CLI,这是一款开源AI代理,允许开发者直接在终端访问Gemini模型。用户只需用个人Google账号登录,即可免费获得Gemini Code Assist许可,体验Gemini 2.5 Pro及其百万token上下文窗口。对于需要更高并发或特定模型的专业开发者,可通过Google AI Studio或Vertex AI按需计费,或选择更高级别的许可。
Vertex AI模型与多模态能力
Gemini 2.5 Flash和2.5 Pro现已在Vertex AI正式上线,主打高速度与复杂推理能力,适合关键业务场景。Veo 3作为文本生成视频模型,现已公测,支持画面与音频生成,能将简单文本转化为具备叙事性的视听内容。例如,输入关于水手的描述,Veo 3可自动生成相应画面与对白。
AI Agent安全与新范式
随着AI代理从“回答问题”转向“自主行动”,安全问题成为焦点。Google Cloud安全团队提出,AI Agent的自主性会放大企业安全盲区,需建立专门的Agent安全体系。安全不仅是技术问题,更需要组织协作,确保AI系统在全生命周期内的安全性。
构建与部署AI应用的实用资源
- Vertex AI服务支持RAG(Retrieval-Augmented Generation)架构,结合Vector Search,提升生成式AI的检索与推理能力。
- 新教程展示如何用Gemini、LangChain和LangGraph构建多模态Agent,实现如目标检测等复杂任务。
- 视频输入微调指南,适用于内容审核、视频字幕和事件定位等场景。
- Gen AI Evaluation Service上线,支持大规模评测、定制rubric和生产环境下的Agent评估。
- Llama4、DeepSeek等主流模型已可通过AI Hypercomputer访问。
企业数据与AI集成
MCP(Model Context Protocol)集成Google Cloud数据库,配合Toolbox,支持多种AI助手(如Claude Code、Cursor等)自动生成数据库查询、设计schema、重构代码等任务,提升开发效率。
近期重要发布与行业合作
- Google I/O期间,发布了Veo 3、Imagen 4、Lyria 2等多模态生成模型。
- Gemini 2.5 Flash/Pro能力扩展,支持“thought summaries”和“Deep Think mode”,提升模型可解释性与推理深度。
- Jules自动化AI编码Agent公测,支持自动写测试、修复bug等。
- Firebase Studio集成Gemini 2.5,支持从Figma导入设计并自动生成全栈应用。
- Cloud Run支持AI Studio一键部署、Gemma 3模型GPU部署及MCP服务器自动化部署。
- llm-d项目推动大规模分布式推理,Google Cloud与多家行业巨头联合贡献。
- Mistral AI、Anthropic Claude等第三方模型已在Vertex AI上线。
安全与合规
- Risk Protection Program升级,涵盖AI相关保险服务。
- Confidential Computing创新,保护敏感AI负载。
- 政府行业应用AI提升威胁检测能力并降低成本。
AI普及与培训
Google Cloud推出面向非技术人员的生成式AI认证及免费培训,帮助企业员工提升AI素养。Vertex AI Studio升级,支持多模态生成模型,简化AI应用开发流程。
真实案例与技术实践
- Gemini 2.5 Pro被用于AI篮球教练,通过多摄像头与AI分析,实现动作捕捉与个性化指导。
- Agent2Agent协议与MCP共同推动多Agent系统互操作,A2A已开源,支持Agent能力发现与协作。
- Vertex AI支持Meta Llama 4、实时API、模型优化器等新特性,提升多模态与大规模应用能力。
领导者观点
Google DeepMind与Google Cloud产品负责人强调多模态AI的实际价值,认为视觉、音频等能力将重塑用户体验和行业应用场景。
总结
Google Cloud正持续推进AI模型、Agent、工具链和安全体系的创新,覆盖开发、部署、评测、安全、合规和行业落地等全链路环节。多模态生成、Agent自治与安全、企业数据集成、开放生态和AI普及培训成为当前重点方向。
推荐阅读

现代前端从传统混编到工程化、自动化体系,经历了Node.js、React等技术革新,实现了模块化、组件化、性能优化和团队协作。复杂性源于用户和业务需求增长,是Web应用进化的必然与价值所在。
深度总结
现代前端的演变与工程化体系
现代前端开发已远超传统网页制作的范畴。它经历了从静态页面到高度模块化、工程化、自动化的深刻转变。当前体系不仅关注页面展示,更强调开发效率、可维护性和用户体验。
传统前端开发的局限
早期前端开发依赖JSP、PHP等模板引擎,配合jQuery进行DOM操作。服务器承担了大部分渲染和计算任务。前后端代码混杂,开发效率低,维护困难。CSS的微小改动可能需要重启整个服务。JavaScript代码分散且全局变量泛滥,缺乏模块化。性能优化和资源管理主要靠手工,工程化能力几乎为零。随着项目规模扩大,这种模式难以支撑复杂业务需求。
工程化的核心诉求
Web应用复杂度提升推动了前端工程化。模块化开发解决了全局变量冲突,提升了代码复用性。组件化UI让页面拆分为独立单元,便于团队协作。自动化构建工具实现了代码压缩、资源合并、缓存处理等优化。热更新和完善的调试工具显著提升了开发效率。
Node.js与本地服务
Node.js的引入是前端工程化的关键。它支持本地开发服务器,实现动态资源响应和模块加载。开发环境下,Node.js可实时编译TypeScript、JSX等,自动推送变更到浏览器。通过本地接口代理,开发者可绕过跨域限制,访问真实后端接口。构建工具如Webpack、Vite等集成于本地服务,实现代码分割、Tree Shaking等优化策略。Node.js让JavaScript贯穿前后端,统一了技术栈。
现代前端框架的技术变革
React、Vue等框架带来了声明式UI、虚拟DOM和高效Diff算法。开发者只需描述界面状态,框架自动处理DOM更新。组件化开发让每个功能单元独立,便于维护和复用。单向数据流和响应式状态管理提升了应用的可预测性和可维护性。与传统jQuery命令式开发相比,现代框架极大简化了复杂UI的构建。
微前端与性能优化
大型应用和多团队协作催生了微前端架构。它借鉴后端微服务思想,将前端拆分为可独立开发、测试、部署的小型应用,提升了团队自主性和技术灵活性。服务端渲染(SSR)回归,优化了首屏加载和SEO。现代性能优化策略包括代码分割、懒加载、缓存策略、虚拟列表、Web Worker、Tree Shaking等。这些手段贯穿开发、构建、部署全流程,确保复杂应用依然具备优异性能。
复杂性的驱动力与价值
前端复杂性源于用户体验、业务需求和开发规模的提升。现代Web应用承载完整业务系统,需支持实时协作、权限管理等复杂逻辑。工程化、模块化、自动化成为必需。性能和体验的极致追求推动了技术创新。回到早期开发模式会导致效率、质量和体验的全面下降。现代复杂性带来了专业化、标准化和创新能力,使前端能够应对更具挑战性的场景。
理解与驾驭复杂性
前端复杂性是为了解决实际问题。每一层抽象和工具的引入,都是为提升开发效率、代码质量和用户体验。理解技术原理、选择合适方案、持续学习核心知识,是应对复杂性的有效路径。技术的最终目标是服务于用户价值,而非复杂本身。
2、先设计再写代码,还是先实现再重构?AI 编程让这种选择变的简单(中文)
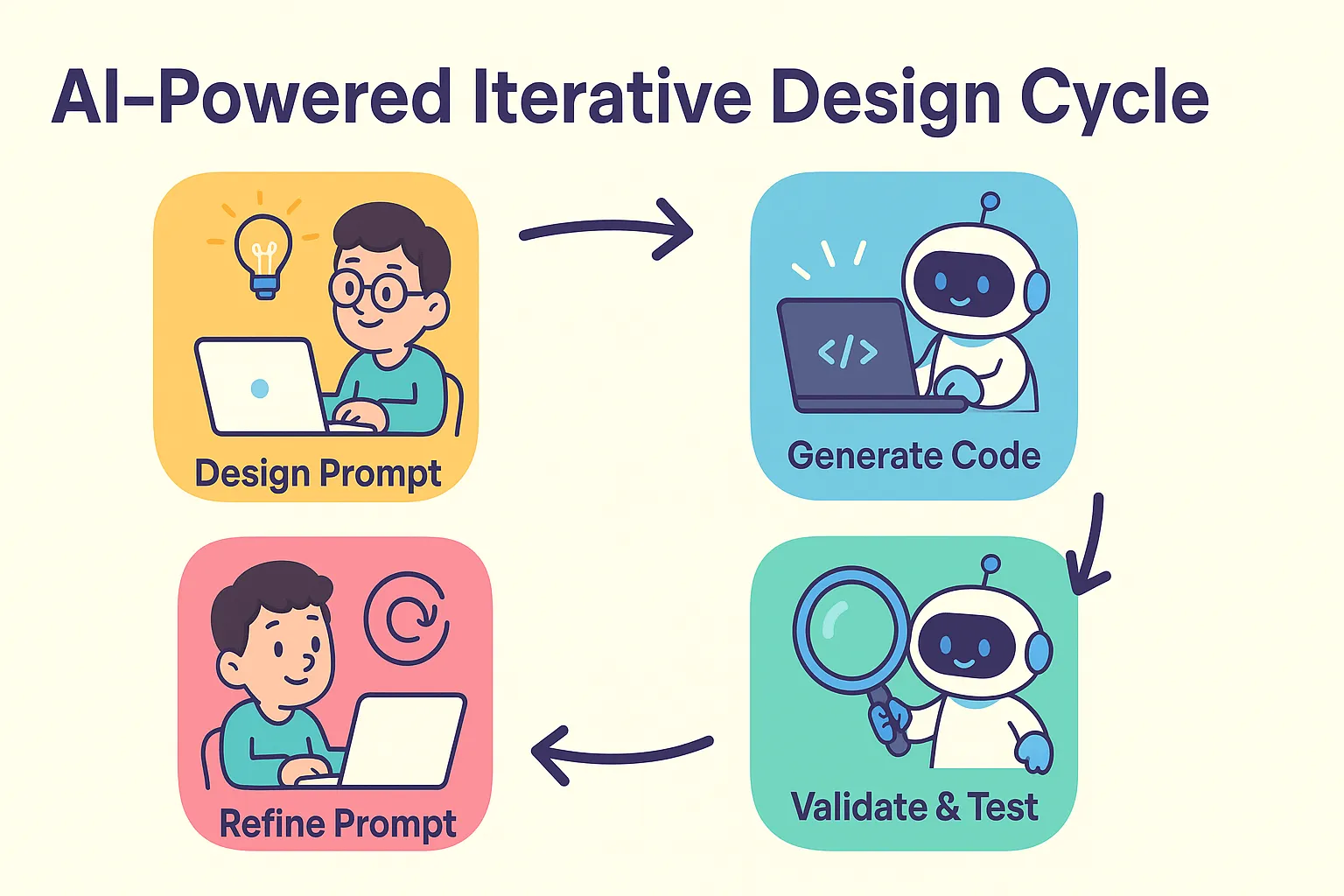
AI 编程融合了“先设计”与“先实现再重构”的优点,通过提示词驱动代码生成与迭代,极大降低了从设计到实现的门槛,使开发流程更高效灵活。开发者需关注小步快跑、及时回滚、自动化测试和代码 Review,以充分发挥 AI 编程的优势。
深度总结
在传统的软件开发流程中,开发者常常面临一个选择:是先进行详尽的系统设计再动手写代码,还是先实现功能,等需求和技术细节逐步明朗后再进行重构。作者回顾了自己在大学学习软件工程时的经历,指出早期的软件工程方法论强调详细设计,这一理念源自建筑工程。然而,软件开发与建筑不同,充满了不确定性。需求和技术方案经常变化,导致详细设计难以落地,实际开发中往往是边写边想,最后再重构。
高水平的架构师可以通过灵活的架构降低变更成本,但这种灵活性本身也会带来维护负担。灵活的架构并非总是收益大于成本。
AI 编程的出现改变了这一局面。AI 极大缩短了从设计到编码的周期。即使详细设计尚不完善,也可以快速实现一个版本,通过实际运行来澄清需求和技术细节。之后再调整设计和实现,过程变得高效且低成本。
作者提出了一种新的开发流程:
- 先进行设计,将设计内容转化为 AI 能理解的提示词。
- 用提示词生成代码。
- 验证生成结果。
- 根据测试反馈调整设计和提示词,重新生成。
在这个流程中,提示词相当于过去的详细设计文档,但形式更灵活,只需 AI 能理解即可。这样做降低了设计到代码的门槛,重构也变得轻松。开发者可以将更多精力投入到系统设计层面,而不是纠结于具体实现。
采用 AI 编程时,需要注意每次生成的代码量不宜过大,否则难以控制。源代码管理变得尤为重要,每次 AI 生成的变更都应记录。AI 生成代码的过程更像是 AI 绘图,不满意就调整提示词重新生成,而不是反复让 AI 修改已有的错误代码。小错误可以修复,大错误应直接回滚并调整提示词或更换模型。
代码 Review 和测试同样不可忽视。每次生成代码后,开发者应仔细检查生成结果,判断其是否符合预期。测试可以通过单元测试和手工测试相结合,尽量降低测试成本,确保每次生成都能快速验证。
对于有经验的开发者,适应 AI 编程可能需要时间。初学者反而更容易接受这种方式。只要有耐心,逐步适应,AI 编程将带来更高效、更灵活的开发体验。
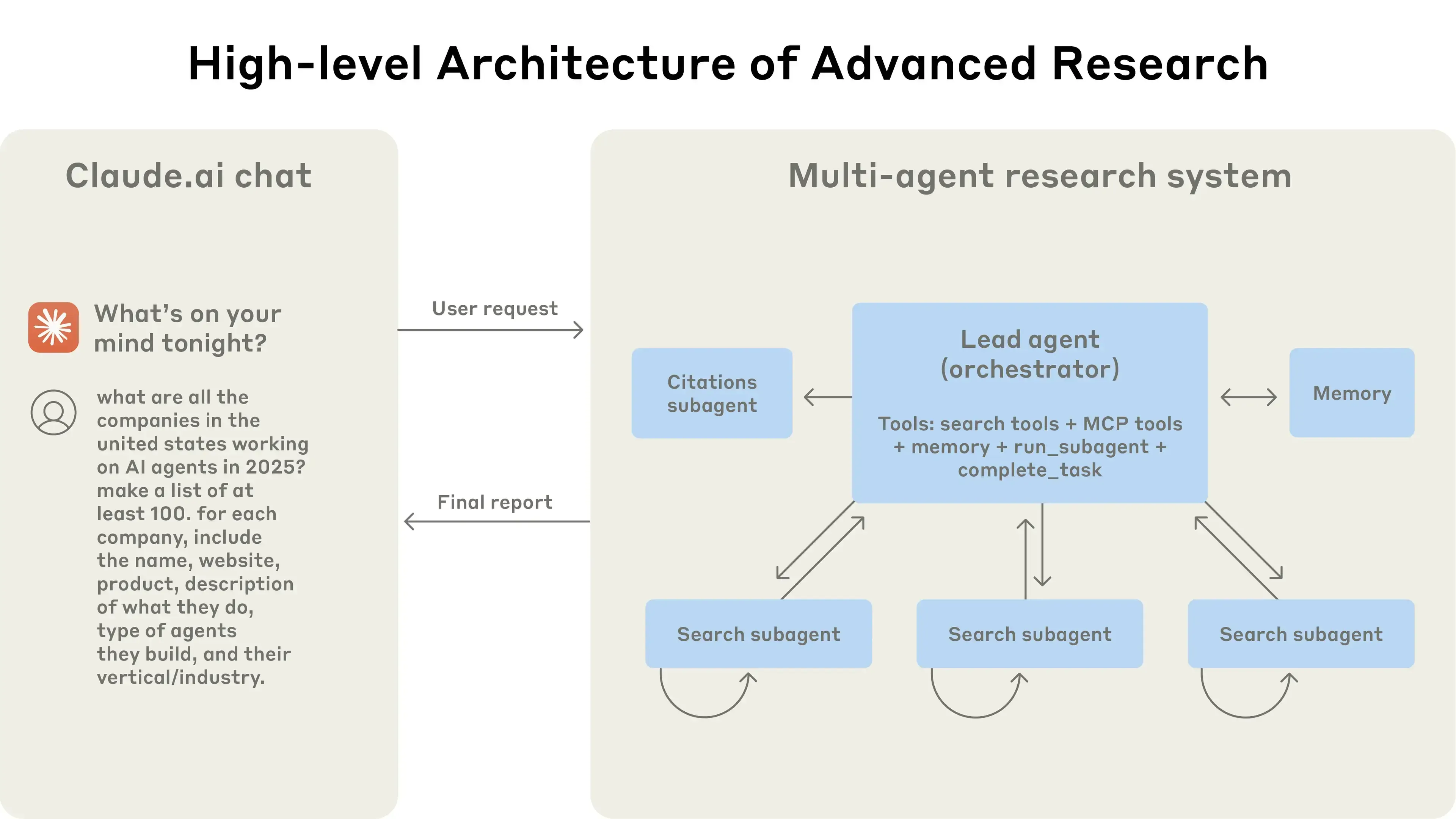
3、多智能体到底该不该建?Anthropic、Cognition 与 LangChain 的三种解法(中文)
三家公司围绕多智能体系统展开辩论,Anthropic强调并行带来的效率提升,Cognition警示高依赖任务下的风险,LangChain则折中指出“上下文工程”为成败关键。多智能体系统适用于高并行、低依赖的场景,写入型复杂任务则优先考虑单体架构。
深度总结
多智能体系统:三家公司的不同解法与核心争议
近期,围绕AI多智能体(Multi-Agent)系统的架构设计,Anthropic、Cognition和LangChain三家公司提出了各自的观点。争议的核心在于:多智能体系统是否值得构建,以及在何种场景下最为适用。
Anthropic:多智能体适合高并发、开放式研究任务
Anthropic团队认为,多智能体系统在处理开放式、动态的研究任务时具有明显优势。其架构采用“协调者-工作者”模式:主智能体负责任务规划和分工,动态生成子智能体并行检索信息,最后由Citation Agent标注引用。这样可以突破单一智能体在context窗口和串行处理上的瓶颈。例如,面对“2025年AI智能体公司”这一研究任务,不同子智能体可分别检索市场预测、公司新闻、技术报告等,主智能体再综合结果。内部测试显示,这种架构在研究任务中的成功率提升约90%。但代价是token消耗巨大,系统运维复杂。
Anthropic总结了多智能体系统的关键经验,包括:任务分派要明确、工具选择需精细、并行化提升效率、引导思维链(Chain of Thought)优化推理过程。多智能体系统适合高价值、需并行处理大量数据并与复杂工具交互的任务,但不适合高依赖性、强一致性的场景。
Cognition:单体架构更适合高一致性任务
Cognition团队以AI编程智能体Devin为例,指出多智能体系统在高一致性任务(如代码生成)中存在严重问题。任务分解和子智能体并行处理容易导致上下文不一致,进而引发逻辑或编译错误。Cognition提出两大原则:一是子智能体必须共享完整决策链,而非仅仅任务文本;二是并行写入时冲突难以自动调解。为此,他们更倾向于单线程长上下文代理,或引入小模型做上下文压缩。这样可以保障任务整体一致性,避免多智能体间的冲突。
Cognition通过实际案例说明,当前多智能体框架在复杂任务中难以落地,主要瓶颈在于上下文同步和智能体间的实时沟通能力。只有当单体智能体具备更强的长上下文处理能力时,多智能体并行才有可能成为主流。
LangChain:灵活选择架构,Context Engineering为核心
LangChain团队认为,争论的焦点应转向“如何灵活构建”多智能体系统。他们总结出两点共识:一是Context Engineering(上下文工程)是构建可靠AI Agent的基础,比Prompt Engineering更为复杂。二是以“读取”为主的多智能体系统(如信息检索)比以“写入”为主的系统(如代码生成)更易于管理。LangChain的LangGraph框架允许开发者精细控制上下文传递和执行步骤,避免隐藏提示和认知架构的强制约束。
LangChain建议,只有当任务价值高、信息面宽且可高度并行时,多智能体系统才值得投入。对于大部分代码任务,单体架构依然更具优势。
结论
三家公司在多智能体系统的适用场景和架构选择上各有侧重。Anthropic强调并行处理和任务分解的优势,Cognition关注一致性和上下文同步的难题,LangChain则主张根据任务特性灵活选择架构,并将Context Engineering作为系统设计的核心。对于前端开发和UI设计等实际应用场景,理解这些架构权衡有助于选择更合适的智能体系统方案。
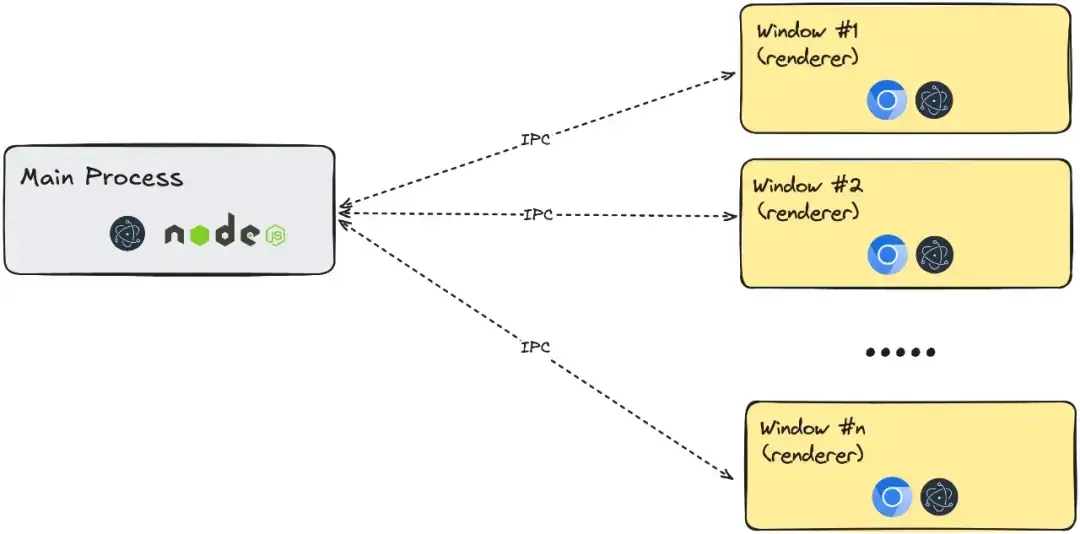
4、Tauri vs. Electron:性能、体积与真实权衡(中文)
Tauri和Electron各有优劣,Tauri以更小体积和更低内存占用适合高性能需求,Electron则凭借成熟生态和开发便捷性依然强大。最终选择需结合实际项目需求和团队能力综合考量。
深度总结
Tauri 与 Electron 的架构与性能对比
本文围绕 Tauri 和 Electron 两大跨平台桌面应用开发框架,系统梳理了它们在架构、性能、包体积、开发体验等方面的差异,并结合实际项目 Hopp 的选型过程,给出了一线开发者的真实权衡。
架构差异
Electron 以 Node.js 作为主进程,应用需自带 Node.js 运行环境。每开一个窗口,都会启动一个独立的渲染进程,本质上相当于运行多个迷你版 Chromium 浏览器。这种架构带来较高的内存和 CPU 占用,但开发体验与 Web 技术高度一致。
Tauri 则以 Rust 作为主进程语言,编译为原生二进制文件,无需捆绑 Node.js。前端界面渲染依赖操作系统自带的 WebView(如 Windows 的 WebView2、macOS 的 WKWebView、Linux 的 WebKitGTK),大幅减小了应用体积。不同平台的 WebView 内核差异,可能导致 UI 表现不一致,需要开发者额外关注。
性能与资源占用
基准测试显示,Tauri 应用的包体积(8.6 MiB)远小于 Electron(244 MiB)。内存占用方面,Tauri 在 macOS 上打开 6 个窗口时约为 172 MB,Electron 则为 409 MB。启动时间两者相近,均能满足日常需求。Tauri 首次构建时间较长,因需编译 Rust,但后续增量构建速度提升明显。
关键特性对比
- 启动时间:两者均表现良好
- 内存占用:Tauri 显著低于 Electron
- 包体积:Tauri 更小
- 后端语言:Tauri 用 Rust,Electron 用 JavaScript
- 构建速度:Electron 更快,Tauri 首次构建较慢
- 浏览器内核:Electron 内置 Chromium,Tauri 利用系统 WebView
Hopp 项目的选型理由
Hopp 选择 Tauri,主要基于以下几点:
- 后端性能:Hopp 需实现低延迟屏幕共享,Rust 的高性能适合处理视频流等计算密集型任务。Electron 实现同等功能需额外管理独立进程,架构更复杂。
- Sidecar 支持:Tauri 原生支持 Sidecar(伴随进程),便于管理外部可执行文件生命周期。Electron 实现类似功能需手动处理进程通信,复杂度更高。
- 功能趋同:Tauri v2 在自动更新、安全性等方面持续追赶 Electron,满足了 Hopp 对性能和安全的高要求。
结论
Tauri 和 Electron 各有优劣。Tauri 以更小的包体积和更低的内存占用,适合对性能和资源敏感的场景。Electron 则凭借成熟的生态和更快的开发迭代,适合追求开发效率的团队。实际选择需结合项目需求、团队技术栈和长期维护成本综合考量。
本方案以纯前端方式实现滑动拼图验证码,巧妙结合DOM结构、样式继承和事件监听,实现了无需后端即可完成的高交互性验证机制,既提升了安全性,也优化了用户体验,适合多场景前端应用。
深度总结
纯前端滑动拼图验证码实现详解
滑动拼图验证码是一种常见的前端交互验证方式,旨在提升用户体验并防止恶意攻击。该方案完全基于HTML、CSS和JavaScript实现,无需后端参与。
核心结构与布局
整个组件分为两个主要区域:验证区域和滑动条区域。验证区域展示一张背景图片,图片上有一个半透明的缺口(目标位置)和一个可滑动的拼图块。滑动条区域包含一个可拖动的滑块和操作提示。
HTML结构简洁明了。.check为验证区域,内部包含.check-content(缺口)和.check-block(拼图块)。.drag为滑动条区域,包含.drag-block(滑块)和.drag-tips(提示文字)。
样式设计要点
验证区域设置固定宽高,背景图片自适应填充。缺口通过绝对定位和半透明背景实现,边框突出显示。拼图块继承父级背景图片,通过调整background-position,确保显示与缺口一致的图片部分。滑动条区域采用浅色背景,滑块颜色醒目,提示文字居中。
交互逻辑拆解
-
随机生成缺口位置
通过random()函数生成缺口的x、y坐标,保证每次验证位置不同。x轴范围为0-325,y轴为0-200,考虑到拼图块尺寸。 -
初始化位置
缺口和拼图块根据随机坐标定位。拼图块的background-position与缺口一致,确保视觉一致性。 -
滑块拖拽机制
鼠标按下滑块时,记录初始x坐标。拖动过程中,计算滑块移动距离,限制在0-350像素范围内。滑块和拼图块同步移动,保持交互一致。 -
验证判定
鼠标释放时,判断滑块当前位置与目标位置的误差。如果在2像素以内,判定为验证成功;否则,滑块和拼图块复位,允许用户重新尝试。
关键实现细节
- 拼图块通过继承背景图片和调整
background-position,实现与缺口区域的精准对齐。 - 拖拽事件采用
mousedown、mousemove和mouseup组合,确保交互流畅。 - 验证逻辑简洁,误差容忍度通过像素范围控制,提升用户体验。
总结
滑动拼图验证码的本质在于前端对图片区域的动态裁切与同步拖拽。通过合理的结构划分、样式继承和事件绑定,实现了无需后端的高效验证机制。该方案适合对安全性和用户体验有较高要求的前端场景。
6、做语音识别现在还能融3000万美金?海外顶级VC押注AI-Native的语音交互,下一个操作系统级的机会!(中文)
Wispr Flow 以“零编辑率”重塑语音输入体验,凭借技术深度和用户洞察,成为语音交互领域的变革者。其产品已实现高留存和付费转化,获得顶级 VC 青睐,预示语音将成为未来主流的人机交互方式。
深度总结
语音交互的变革与Wispr Flow的技术路径
键盘作为人机交互的主流方式已存在150年,但其效率早已无法匹配人类思维的速度。随着移动设备普及,打字速度反而下降,成为表达想法的瓶颈。Wispr Flow试图用语音彻底取代键盘,推动人机交互进入新阶段。
Wispr Flow的核心创新
传统语音识别系统关注“单词错误率”,即识别文本中单词的准确率。即使准确率高达99%,每个句子仍可能有错误,导致用户不得不频繁修改。Wispr Flow转而优化“零编辑消息率”,即用户无需修改即可直接发送的消息比例。系统不仅识别语音,更理解意图,将口语转化为结构化、清晰的文本。用户体验因此大幅提升,80%的消息无需编辑,且用户粘性极高。
创始人背景与团队能力
创始人Tanay Kothari自幼编程,具备极强的自学和专注能力。其早期项目ConvertCC在13岁时实现病毒式增长,后续创业FeatherX被Cerebras收购。团队成员多为机器学习领域专家,具备深度定制模型的能力。联合创始人Sahaj Garg在扩散模型领域有突出贡献,为产品的技术深度提供保障。
技术实现与产品哲学
Wispr Flow不将模型本身视为终点,而是持续优化模型行为。例如,通过微调大语言模型,显著降低幻觉率。系统支持104种语言,能够理解用户的说话习惯和专业术语,实现高度个性化。产品策略聚焦文本输入场景,逐步扩展至更广泛的AI助手功能,避免“功能泛滥但体验平庸”的陷阱。
市场时机与用户需求
大语言模型的成熟、用户对自然语言交互的期待提升、移动设备输入的局限性,以及远程办公环境的普及,共同推动了语音交互的需求。Wispr Flow的用户分布广泛,40%在美国,30%在欧洲,30%在其他地区,且30%以上为非技术背景用户,显示出语音交互的普适性。
投资逻辑与行业影响
顶级风投如Menlo Ventures、NEA等积极押注Wispr Flow,认为其有望成为新的输入层,重塑人机交互格局。产品的高用户转化率和粘性,验证了其市场潜力。语音交互不仅提升效率,还可能重塑工作方式和生活习惯。
未来展望与挑战
语音交互的普及将带来隐私保护、文化适应、技术成熟度等新挑战。行业需关注数据安全和多语言、多口音的适配。语音不会完全取代其他交互方式,但将成为主流之一。Wispr Flow的案例表明,技术革命往往源于对问题本质的重新定义,而非对现有方案的简单优化。
结语
Wispr Flow以用户为中心,重构了语音交互的技术路径和产品体验。其发展路径为从业者提供了关于人机交互未来的有力参考。语音输入的普及将推动技术更好地服务于人类,降低数字门槛,提升整体效率与体验。
7、Swift 官方正式支持 Android,iOS 的跨平台春天要来了吗?(中文)
Swift 官方宣布支持 Android,利用 LLVM 和 NDK 实现原生编译,基础库已可用,但 UI 框架和互操作仍需完善,整体尚处于初级阶段,未来可期。
深度总结
Swift 官方支持 Android:跨平台新进展
Swift 官方已宣布成立 Android 工作组,将 Android 纳入官方支持平台。该举措的核心目标是为 Swift 语言添加并维护 Android 平台支持,使开发者能够直接用 Swift 开发 Android 应用。
技术实现方式
Swift 跨平台并非首次出现。此前如 Skip 方案,是将 Swift 代码翻译为 Kotlin,并将 SwiftUI 转换为 Compose。但 Swift 官方的做法不同,采用 LLVM 进行适配。LLVM 是众多跨平台框架的基础,Android NDK 也基于 LLVM 的 Clang 作为官方 C/C++ 编译器。自 NDK r11 起,Clang 成为推荐编译器,GCC 逐步被弃用。
Swift 编译器自诞生起就基于 LLVM,这为其适配 Android 提供了技术基础。通过 Android NDK,Swift 编译器可为 Android 支持的多种 CPU 架构(如 aarch64、armv7、x86_64)生成原生机器码。编译产物为 so 文件,可在 Android 设备上直接运行或被标准 Android 应用加载。
编译与部署流程
开发者需在 Linux 环境(推荐 Ubuntu 20.04/22.04)下,使用 Swift 官方交叉编译工具链,将 .swift 源文件编译为可执行文件或共享库。编译产物及必需的 Swift 运行时库通过 adb 推送到 Android 设备。最终,开发者可在 Android shell 环境中直接运行这些原生代码,或通过 JNI 规范在标准 Android 应用中调用。
现有支持与局限
目前,Swift 的核心标准库(stdlib)已能在 Android 平台编译,基础数据类型如 String、Int、Array、Dictionary 已获得支持。更高层次的库如 Foundation(URLSession、JSONEncoder)和 Dispatch(并发支持)正在移植中。
UI 层面,Swift 官方尚未提供任何支持 Android 的 UI 框架。官方文档明确指出,开发者需自行选择或实现 UI 框架。当前形态下,Swift on Android 更像 Kotlin Multiplatform(KMP),而非 Compose Multiplatform(CMP)。如需 UI 层的官方适配,仍需等待 SwiftUI 的后续支持。
互操作性
历史上曾有 swift-java 等尝试,目标是实现 Swift 与 Java 的双向互操作。当前 Swift on Android 并未直接提供桥接绑定,开发者需自行实现。若需让 Swift 函数被 C 代码或 JNI 调用,可通过 @_cdecl 属性将函数暴露为 C 语言标准符号。
现阶段评价
Swift on Android 目前在交互和 UI 层面仍显粗糙,主要提供了底层能力的开源实现。对于希望用 Swift 跨平台开发的开发者而言,这一进展意味着官方已迈出关键一步,但距离生产级标准尚有距离。UI 框架和高阶库的完善将是未来关注重点。
8、TC39 推进九项 JavaScript 提案,包括 Array.fromAsync、Error.isError 和 Using(英文)
TC39将Array.fromAsync、Error.isError和using三项关键特性纳入JavaScript标准,分别提升了异步数据收集、跨域错误判断和资源管理的便捷性与安全性。其他提案如Import Attributes等也在持续推进中。
深度总结
TC39推进九项JavaScript提案,三项进入标准
Ecma Technical Committee 39(TC39)近期将九项JavaScript提案推进到更高阶段,其中Array.fromAsync、Error.isError和using三项已正式纳入ECMAScript标准。
Array.fromAsync:异步数据收集的新方式
Array.fromAsync为异步可迭代对象提供了直接转为数组的能力。以往开发者需要手动编写for await…of循环来收集异步数据。现在,Array.fromAsync可以一行代码完成同样的任务。例如,处理异步管道时,原本需要:
async function toArray(items) { const result = []; for await (const item of items) { result.push(item); } return result; }
有了Array.fromAsync,直接写成:
const result = await Array.fromAsync(pipeline.execute([1, 2, 3, 4, 5]));
这种方式简化了异步数据的收集流程,提升了代码可读性和维护性。
Error.isError:跨环境判断Error实例
Error.isError方法为判断一个值是否为Error实例提供了更可靠的方式。传统的instanceof Error在跨realm(如iframe或Node的vm模块)时会失效。Error.isError解决了这一局限,无论Error对象来自哪个环境,都能准确识别。
using:显式资源管理
Explicit Resource Management引入了using声明,用于管理需要显式释放的资源,如文件或网络连接。以往,开发者需要手动调用close或releaseLock等方法,且在多个资源管理时容易出错。例如,如果a.close()抛出异常,b.close()可能永远不会被执行。using语法统一了资源释放流程,减少了资源泄漏的风险。
其他提案进展
Import Attributes(原Import Assertions)进入Stage 3,允许在import声明中添加元数据,指定模块类型(如JSON或CSS)。Promise.try、RegExp.escape等提案也在推进中,分别用于简化Promise链的错误处理和正则表达式中的字符串转义。
TC39提案流程简介
每个ECMAScript新特性需经历五个阶段:Strawman、Proposal、Draft、Candidate、Finished。只有进入Stage 4的特性才会被纳入标准。实际浏览器支持可能会滞后于标准的发布。
开源精选
1、Pythagora-io/gpt-pilot(Star:33k):一款开源AI开发者工具,能够与开发者协作,自动生成、调试并完善生产级应用的大部分代码。
2、h3js/h3(Star:4.5k):一个为高性能和可移植性打造的极简H(TTP)框架。
3、cthackers/adm-zip(Star:2.1k):一个纯JavaScript实现的Node.js库,用于创建和解压zip文件,支持内存和磁盘操作。
4、actions/toolkit(Star:5.4k):GitHub 官方提供的一套用于简化自定义 GitHub Actions 开发的工具包集合。
5、eemeli/yaml(Star:1.5k):一个用于 JavaScript 的 YAML 解析与字符串化库,支持 YAML 1.1 和 1.2 标准,兼容多种数据模式,适用于 Node.js 和现代浏览器。
6、vfile/to-vfile(Star:67):一个用于从文件路径创建虚拟文件并进行文件系统读写的vfile工具。
7、unifiedjs/unified(Star:1.3k):一个用于通过插件解析、检查、转换和序列化内容(AST语法树)的核心包和生态集合。
8、remarkjs/remark-gfm(Star:945):remark-gfm 是一个用于为 remark 添加 GitHub Flavored Markdown(GFM)扩展(如自动链接、脚注、删除线、表格、任务列表)支持的插件。
9、remarkjs/remark-rehype(Star:302):将 Markdown 语法树(mdast)转换为 HTML 语法树(hast),实现 remark 到 rehype 的桥接,方便 Markdown 转 HTML 及 rehype 插件生态的使用。
10、remarkjs/remark(Star:8.3k):一个强大的Markdown处理器,通过插件实现对Markdown内容的转换和操作。
11、withastro/starlight(Star:6.8k):一个用于Astro的文档网站框架,旨在构建美观、可访问、高性能的文档网站。
12、yargs/cliui(Star:375):用于轻松创建复杂的多列命令行界面布局的工具库。
13、sindresorhus/type-fest(Star:15.6k):一个收集了大量实用 TypeScript 类型定义的库,帮助开发者更高效地进行类型编程。
14、isaacs/minimatch(Star:3.4k):一个用于将 glob 表达式转换为 JavaScript 正则表达式并进行路径匹配的极简库,广泛用于 npm 内部实现。
15、yargs/yargs(Star:11.3k):yargs 是一个为 Node.js 提供命令行参数解析和交互式 CLI 构建的现代库。
16、raszi/node-tmp(Star:754):一个用于在Node.js环境中创建临时文件和目录的库。
17、jprichardson/node-fs-extra(Star:9.6k):为 Node.js 的原生 fs 模块提供了额外的文件系统方法(如 copy、remove、mkdirs 等)并支持 Promise,旨在成为 fs 的无缝替代品。
18、isaacs/node-glob(Star:8.6k):一个为 Node.js 提供 shell 风格文件匹配(glob)功能的高正确性和高性能 JavaScript 实现。
19、fb55/css-select(Star:570):一个高性能的 CSS 选择器编译器和引擎,可将 CSS 选择器编译为函数并高效查询/匹配 DOM 元素。
20、Rich-Harris/magic-string(Star:2.6k):一个用于高效操作字符串和生成sourcemap的JavaScript工具库。
21、koodo-reader/koodo-reader(Star:22.8k):一个现代的电子书管理器和阅读器,支持多平台同步和备份。